| *** ryohayakawa has joined #opendev | 00:09 | |
| corvus | clarkb: sn5 sucessfully hopped :) | 00:45 |
|---|---|---|
| ianw | i had it up, then there were comments it was scrubbed, so i closed it, and then it went | 00:55 |
| *** xiaolin has joined #opendev | 01:23 | |
| *** hashar has joined #opendev | 01:29 | |
| *** mtreinish has joined #opendev | 02:39 | |
| *** hashar has quit IRC | 03:50 | |
| *** tkajinam has quit IRC | 03:51 | |
| *** tkajinam has joined #opendev | 03:52 | |
| *** fressi has joined #opendev | 04:27 | |
| donnyd | its looks like something is actual busted... so maybe my upgrade didn't go as smoothly as I thought... | 04:33 |
| openstackgerrit | Ian Wienand proposed opendev/system-config master: launch-node: get sshfp entries from the host https://review.opendev.org/744821 | 04:39 |
| ianw | fungi/clarkb: ^ one to try if launching a new node | 04:39 |
| ianw | donnyd: thanks ... if it was easy everyone would do it :) | 04:40 |
| donnyd | I want to say that its possible we have an issue with the number of images being uploaded - it appears its trying to upload 322 images at the moment | 04:41 |
| donnyd | https://www.irccloud.com/pastebin/AN173WWP/ | 04:42 |
| donnyd | i am going to purge those that are stuck in queued | 04:44 |
| donnyd | just some rough maths - that would be about 3.2 TB worth of images... it may take some time to get caught up | 04:47 |
| *** sgw2 has quit IRC | 04:49 | |
| *** raukadah is now known as chkumar|rover | 04:54 | |
| ianw | umm, yes that is not correct :) | 04:54 |
| ianw | 2020-08-03 16:16:45 UTC deleted corrupt znode /nodepool/images/fedora-31/builds/0000011944 to unblock image cleanup threads | 04:55 |
| ianw | that might be related? | 04:56 |
| ianw | donnyd: afaics nodepool doesn't think it's uploading to OE at the moment. so might be collateral damage from prior issues | 04:58 |
| openstackgerrit | OpenStack Proposal Bot proposed openstack/project-config master: Normalize projects.yaml https://review.opendev.org/744822 | 06:07 |
| donnyd | ianw: it looks like the images are uploaded now | 06:25 |
| donnyd | there are still a couple saving.. but it does appear to "work" | 06:25 |
| donnyd | https://usercontent.irccloud-cdn.com/file/9NT9nqqh/image.png | 06:25 |
| donnyd | and I was able to delete the instance that was stuck in error | 06:27 |
| donnyd | I think what happened is I reduced the available memory for my DB nodes while I was shuffling things around because they weren't really in use - so i forgot to set them back to normal | 06:28 |
| donnyd | and when I looked at the db nodes two of them were all but locked up.. took several minutes to even open an ssh session... so I am thinking they are sorted and we can maybe give it another swing | 06:29 |
| donnyd | i have run a few tests to ensure the focal image that was uploaded does in fact boot and start | 06:39 |
| *** ryohayakawa has quit IRC | 07:02 | |
| *** tosky has joined #opendev | 07:38 | |
| openstackgerrit | Merged openstack/project-config master: Normalize projects.yaml https://review.opendev.org/744822 | 07:41 |
| *** DSpider has joined #opendev | 07:43 | |
| *** moppy has quit IRC | 08:01 | |
| *** moppy has joined #opendev | 08:03 | |
| *** dtantsur|afk is now known as dtantsur | 08:04 | |
| *** tosky has quit IRC | 08:26 | |
| *** tosky has joined #opendev | 08:27 | |
| ianw | donnyd: ok, so it seems to boot, but i can't log in | 08:41 |
| ianw | [ 29.577671] cloud-init[2011]: ci-info: no authorized SSH keys fingerprints found for user ubuntu. | 08:41 |
| ianw | i feel like it's not getting keys; meta-data problem? | 08:41 |
| ianw | b4622148-ea50-46a9-85a5-24f3c08d565d i've left in this state | 08:41 |
| ianw | (key is in /tmp from launch attempt on bridge.openstack.org) | 08:42 |
| *** sshnaidm|afk is now known as sshnaidm | 08:56 | |
| *** bolg has joined #opendev | 09:59 | |
| *** tkajinam has quit IRC | 10:15 | |
| *** hashar has joined #opendev | 11:08 | |
| openstackgerrit | Aurelien Lourot proposed openstack/project-config master: Mirror keystone-kerberos and ceph-iscsi charms to GitHub https://review.opendev.org/744890 | 11:54 |
| donnyd | ianw: I rebooted the node and it seems to have gotten meta-data | 12:06 |
| *** hashar has quit IRC | 12:13 | |
| donnyd | oh i see the error ianw | 12:48 |
| donnyd | the metadata service is in fact also busted | 12:48 |
| donnyd | https://www.irccloud.com/pastebin/Rz47du4u/ | 12:50 |
| donnyd | https://www.irccloud.com/pastebin/snUVY2y4/ | 12:50 |
| donnyd | its fixed now | 12:50 |
| donnyd | I left a hosts entry in the edge machine that was trying to contact the internal metadata service on ipv6 and it was not very happy about this | 12:51 |
| *** priteau has joined #opendev | 13:09 | |
| *** iurygregory has quit IRC | 13:12 | |
| *** sgw1 has joined #opendev | 13:15 | |
| *** iurygregory has joined #opendev | 13:18 | |
| openstackgerrit | Merged openstack/project-config master: Move non-voting neutron tempest jobs to separate graph https://review.opendev.org/743729 | 13:22 |
| openstackgerrit | Aurelien Lourot proposed openstack/project-config master: Mirror keystone-kerberos and ceph-iscsi charms to GitHub https://review.opendev.org/744890 | 13:29 |
| openstackgerrit | Oleksandr Kozachenko proposed openstack/project-config master: Add openstack/barbican in required project list of vexxhost https://review.opendev.org/744909 | 14:04 |
| *** sshnaidm is now known as sshnaidm|afk | 14:24 | |
| *** redrobot has joined #opendev | 14:32 | |
| *** mlavalle has joined #opendev | 14:37 | |
| *** hashar has joined #opendev | 15:01 | |
| openstackgerrit | Merged openstack/project-config master: Add openstack/barbican in required project list of vexxhost https://review.opendev.org/744909 | 15:15 |
| *** chkumar|rover is now known as raukadah | 15:26 | |
| *** tosky has quit IRC | 15:31 | |
| *** shtepanie has joined #opendev | 16:00 | |
| *** tosky has joined #opendev | 16:29 | |
| openstackgerrit | Sean McGinnis proposed openstack/project-config master: Gerritbot: only comment on stable:follows-policy repos https://review.opendev.org/744947 | 16:30 |
| *** dtantsur is now known as dtantsur|afk | 16:39 | |
| *** sshnaidm|afk is now known as sshnaidm | 17:19 | |
| *** priteau has quit IRC | 17:38 | |
| *** fressi has quit IRC | 17:42 | |
| *** shtepanie has quit IRC | 18:40 | |
| clarkb | fungi: when pbr isn't distracting you I'd love your thoughts on https://review.opendev.org/#/c/744795/1 and what testing looks like | 19:12 |
| clarkb | thats the gerritbot change | 19:12 |
| clarkb | I'll sync up with ianw on his comments later today and try to get a new ps up that is mergeable | 19:14 |
| *** hashar has quit IRC | 19:32 | |
| *** tosky has quit IRC | 19:39 | |
| *** DSpider has quit IRC | 20:08 | |
| clarkb | fungi also following up on the sshfp stuff for review are we all set there? the opendev.org zone update landed and openstack.org cname was updated? | 20:09 |
| clarkb | the nodepool upload workers update has applied so we should upload more quickly now | 20:10 |
| * clarkb is catching up on yesterdays todo list | 20:10 | |
| fungi | oh, i haven't done the openstack.org update yet, will get to that in just a sec | 20:13 |
| openstackgerrit | Oleksandr Kozachenko proposed openstack/project-config master: Add openstack/barbican-tempest-plugin to vexxhost https://review.opendev.org/744982 | 20:23 |
| Open10K8S | HI team | 20:40 |
| Open10K8S | Please check this https://review.opendev.org/744982. Needed-By: https://review.opendev.org/#/c/744912/ | 20:41 |
| *** smcginni1 has joined #opendev | 20:47 | |
| *** smcginnis has quit IRC | 20:50 | |
| *** smcginni1 is now known as smcginnis | 20:50 | |
| openstackgerrit | Merged openstack/project-config master: Add openstack/barbican-tempest-plugin to vexxhost https://review.opendev.org/744982 | 20:51 |
| openstackgerrit | Tristan Cacqueray proposed zuul/zuul-jobs master: shake-build: add shake_target variable https://review.opendev.org/744990 | 21:09 |
| *** tosky has joined #opendev | 21:25 | |
| *** markmcclain has quit IRC | 21:53 | |
| ianw | clarkb: my thought was that it has to listen to the event stream right? so it has to connect to the remote host, so review-test needs a key installed? | 22:15 |
| clarkb | ianw: it does, but it may be sufficient to test that the docker container starts? | 22:16 |
| clarkb | and then just let it error? | 22:16 |
| ianw | yeah, that was the chicken egg i was thinking ... how do you get the authorized key on the remote side? i can't see a way | 22:16 |
| ianw | it is probably enough that the container starts and we see a log file or something | 22:17 |
| clarkb | right, my question about key material was more do we want a real key there so that paramiko loads it successfully but not necessarily add it to the server so that it can then connect successfully | 22:19 |
| clarkb | I'm not sure where the useful line is | 22:19 |
| ianw | ahh, ok; sorry yes i was thinking total end-to-end | 22:19 |
| ianw | i wouldn't mind; if it's easier to detect the daemon starting with a valid but useless key ("can't log in" v throwing an exception because the key isn't parsed, say) i'd go with the fake key :) | 22:21 |
| clarkb | cool I'll generate a fake key then | 22:22 |
| *** qchris has quit IRC | 22:22 | |
| clarkb | though I've been distracted by pbr things | 22:24 |
| ianw | donnyd: thanks, let me give it another go :) | 22:28 |
| ianw | (i'm assuming fungi/clarkb didn't as yet?) | 22:28 |
| fungi | i have not, no | 22:29 |
| fungi | still somewhat consumed by personal post-storm activities/cleanup | 22:29 |
| clarkb | I didn't. Sorry totally sniped by the pbr thing. Hoping to fix it so that the same issue doens't pop up every month | 22:29 |
| ianw | i will have to read backscroll on pbr ... do i want to? ;) | 22:29 |
| fungi | most discussion was in #openstack-infra with some in #openstack-oslo | 22:30 |
| clarkb | ianw: tl;dr is people keep trying to drop python2 support in pbr | 22:30 |
| clarkb | but since pbr is a setup_requires we can't really do that without breaking stable branches that still run on python2 | 22:30 |
| fungi | tl;dr is that pbr's testing was neglected for far too long and siuffered excessive bitrot | 22:30 |
| ianw | fungi: bummer ... all ok? i have nothing but time. we're on a 6 week lockdown where you're supposed to go out within a 5km radius for 1 hour a day, and a total curfew from 8pm-5am | 22:30 |
| clarkb | and ya its really just the pbr testing that bit rotted and needs fixing. pbr itself is fine when running | 22:30 |
| fungi | ianw: yeah, we didn't get hit that hard, but now have to undo all our storm prep (until the next one) | 22:31 |
| fungi | lots of stuff in the living space which normally goes downstairs in the entry or garage, things moved to the non-windward side of the house need to be moved back, and so on | 22:32 |
| clarkb | fungi: have you ocnsidering converting your home into a boat? | 22:33 |
| clarkb | then with a good anchor you can float through the storms? | 22:33 |
| fungi | it's halfway there, but too leaky | 22:33 |
| fungi | it would sink | 22:33 |
| fungi | much of our disposable income goes toward making it increasingly seaworthy | 22:34 |
| *** qchris has joined #opendev | 22:35 | |
| fungi | er, i meant stuff we moved from the leeward side of the house to the windward side has to be moved back, those always trip me up | 22:35 |
| * fungi is clearly not a career sailor | 22:35 | |
| fungi | it's always confused me that "windward" is the side away from the wind | 22:36 |
| fungi | er, no, i had it right the first time | 22:38 |
| fungi | i guess the confusion is that if you're moving windward you're moving with the wind but the windward side is what faces the wind | 22:39 |
| clarkb | ya ist direction related | 22:40 |
| fungi | once we finish sealing the hull and weigh anchor i'm sure i'll figure it out | 22:42 |
| donnyd | yea we should be good this time around.. but I am sure i have said that before | 22:48 |
| ianw | ... ok ... trying hte mirror bringup | 22:58 |
| * donnyd crosses fingers his cloud isn't still busted | 22:59 | |
| ianw | it's up, logged in, ipv4 & ipv6 working ... looking good! | 22:59 |
| * donnyd jumps in excitement that he didn't ask ianw to keep working on a busted cloud | 23:00 | |
| *** tkajinam has joined #opendev | 23:00 | |
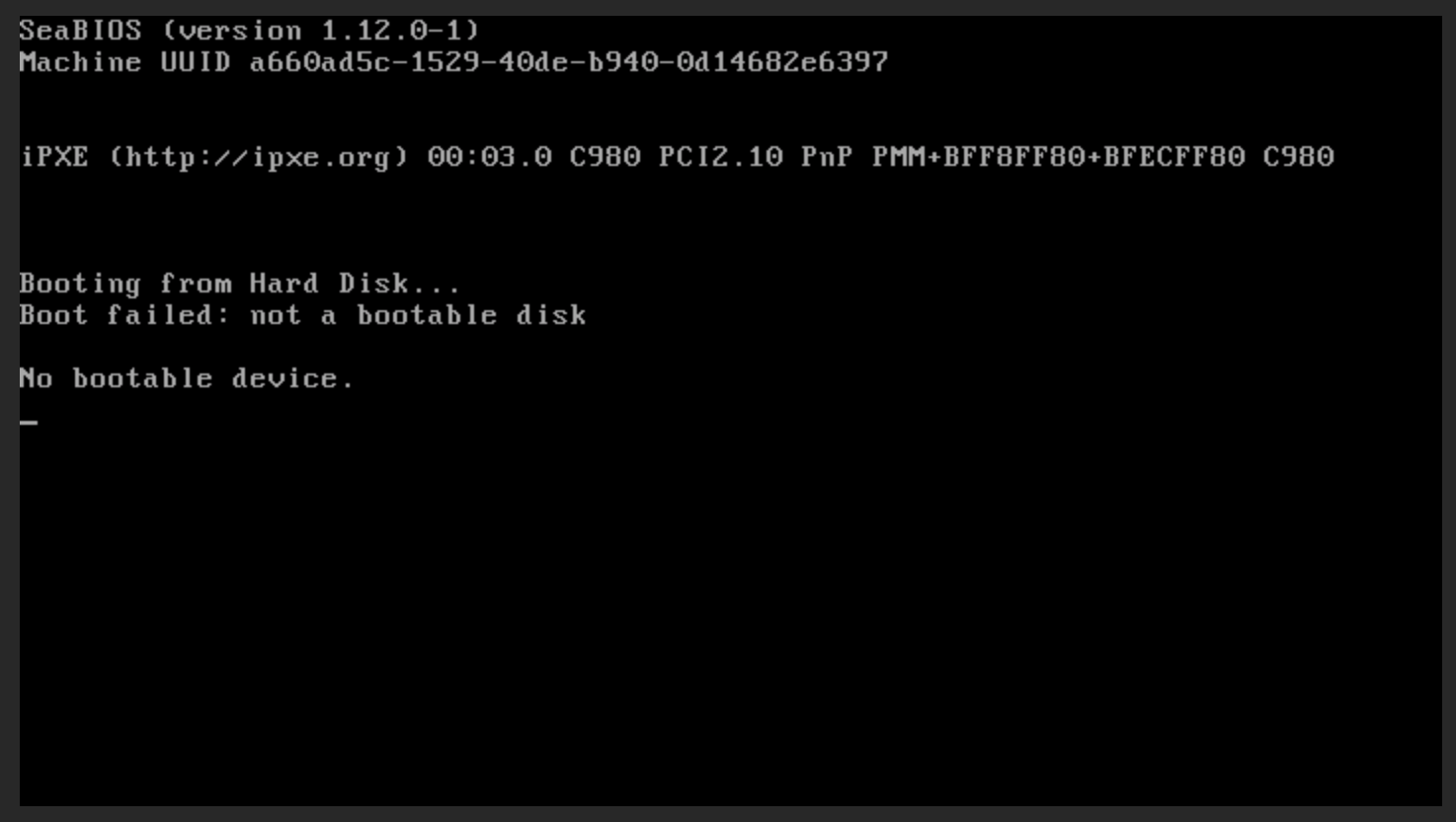
| mnaser | infra-root: we just upgraded nova in the montreal datacenter and it _looks_ like nodepool is spinning through vms very quickly (almost as if it's deciding "this vm is not ok, scrap it" rate of speed) | 23:00 |
| mnaser | i'm seeing them disappear before i can even check the console | 23:01 |
| donnyd | i ran some tests earlier launching 30 instances at a time and making sure they came up properly - nothing was failing.. but it normally doesn't fail on the local network | 23:01 |
| mnaser | now it also looks like they're not pingable so i wonder if this is some glean thing | 23:01 |
| mnaser | cause we can boot our images (which use cloud-init) just fine | 23:02 |
| donnyd | is there a particular OS or is it all of them mnaser | 23:02 |
| ianw | mnaser: umm ... config-drive related maybe? no glean changes afaik | 23:02 |
| mnaser | donnyd: i havent looked if its a specific os | 23:02 |
| ianw | let me see if i can pull anything from logs | 23:02 |
| donnyd | when we had glean issues on OE it was just a single OS that was angry | 23:03 |
| donnyd | I want to say is was centos, but I don't remember THB | 23:04 |
| mnaser | https://usercontent.irccloud-cdn.com/file/R35RhXAO/image.png | 23:04 |
| donnyd | that is not good at all | 23:04 |
| mnaser | that'll do it | 23:04 |
| donnyd | is that all images or just one type? anyway for you to check? | 23:05 |
| mnaser | i'm seeing other vms going up just fine | 23:05 |
| mnaser | it's pretty hard because i have like | 23:05 |
| mnaser | 2 minutes before nodepool kills it | 23:05 |
| clarkb | we have had corrupted images before | 23:06 |
| clarkb | there is no hash verification anywhere | 23:06 |
| clarkb | is it possible that upgrading nova happened during an upload and that truncated things in a bad way? | 23:06 |
| clarkb | mnaser: you can boot the image instead to debug rather than rely on nodepool? | 23:06 |
| clarkb | if you'd prefer I can do that too | 23:07 |
| donnyd | do you use ceph for the glance backend mnaser ? | 23:07 |
| mnaser | clarkb: that might be a case, and it might be easier for you to do it than me. i'd have to give myself access to the tenant and all that | 23:07 |
| clarkb | ok I'll spin one up. this is mtl right? | 23:08 |
| clarkb | ya-cmq-1 or whatever | 23:08 |
| mnaser | yeah | 23:08 |
| ianw | i'm just looking at the logs on nl03 now to see what i can ... glean | 23:08 |
| clarkb | mnaser: do you know what image the boots are failing on? | 23:09 |
| clarkb | name or uuid is good for me | 23:09 |
| mnaser | clarkb: i think majority seem to be `ubuntu-bionic-1596656540` | 23:09 |
| *** mlavalle has quit IRC | 23:09 | |
| ianw | i see 149 failed launch attempts there | 23:10 |
| mnaser | yeah, the thing is i can launch vms normally just fine (and using our images) | 23:10 |
| donnyd | mnaser: I think I have that image - let me fire one off and see what it does on my end | 23:10 |
| mnaser | ianw: are you able to tell when that image was uploaded? ^ | 23:11 |
| clarkb | mnaser: clarkb-test1 has started it has uuid 834d1d5e-f28e-4136-a1fe-89761643db7a | 23:11 |
| clarkb | mnaser: | updated_at | 2020-08-05T21:17:03Z for that image | 23:12 |
| *** markmcclain has joined #opendev | 23:12 | |
| clarkb | about 2 hours ago | 23:12 |
| ianw | mnaser: ok, i agree, all of the bad launches are on bionic | 23:12 |
| donnyd | nope, I only have ubuntu-bionic-1596656541 | 23:12 |
| ianw | actually no ... sorry | 23:12 |
| clarkb | that image is "only" 13GB or so | 23:13 |
| clarkb | I'm trying to figure out what the source image size is | 23:13 |
| mnaser | hmm | 23:13 |
| mnaser | the image on disk is | 23:13 |
| mnaser | 258K | 23:13 |
| fungi | that's some amazing compression you've got | 23:13 |
| mnaser | \o/ | 23:13 |
| mnaser | let me check what the size is in ceph | 23:13 |
| ianw | # grep -f bad-launch.txt launcher-debug.log | grep 'from image' | grep vexxhost-ca-ymq-1 | awk '{print $20}' | sort | uniq -c | 23:13 |
| ianw | 24 centos-7 | 23:13 |
| ianw | 155 centos-8 | 23:13 |
| ianw | 324 ubuntu-bionic | 23:13 |
| ianw | 15 ubuntu-focal | 23:13 |
| ianw | that maybe just reflects the distribution of our testing | 23:14 |
| donnyd | mnaser: share your compression secrets with the world... you may save someone a billion or two | 23:14 |
| *** tosky has quit IRC | 23:14 | |
| ianw | s/vexxhost/pied piper/ | 23:14 |
| fungi | store the extra bits in a quantum pocket universe | 23:14 |
| clarkb | 17921081344 is the correct size according to nodepool's fs | 23:14 |
| clarkb | so ya I think thats a corrupted upload | 23:14 |
| corvus | oh i'm around if there's an urgent thing; was deep into k8s stuff in another window | 23:15 |
| mnaser | `rbd -p images info 05fbc2ad-8aa6-4cd6-bd2b-eee942034cf9` => size 13 GiB in 1615 objects | 23:15 |
| clarkb | the fix is to delete the upload in vexxhost and have it reupload | 23:15 |
| clarkb | corvus: I think its not that urgent | 23:15 |
| corvus | k; ping me if you need me | 23:15 |
| clarkb | corvus: or at least we're close to figuring it out / fixing it | 23:15 |
| mnaser | so i guess it _maybe_ not related to the ugprade | 23:15 |
| clarkb | mnaser: unless the upgrade somehow truncated the image? | 23:15 |
| fungi | unless the upgrade somehow interrupted the upload | 23:15 |
| clarkb | I think we should delete the upload and have it reupload and go from there | 23:16 |
| mnaser | glance has been on ussuri since a few days ago | 23:16 |
| fungi | in a way that nodepool didn't recognize as a failure | 23:16 |
| clarkb | fungi: well glane doesn't check hashes or anything | 23:16 |
| fungi | clarkb: i concur | 23:16 |
| mnaser | this was only nova, and i think ianw confirmed more than 1 failure | 23:16 |
| clarkb | fungi: its really hard for nodepool to know if thta fails :( | 23:16 |
| donnyd | that is pretty interesting - i have 6.23gb image size for ubuntu-bionic-1596656541 | 23:16 |
| fungi | and yes, glance's checksums are really just cosmetic | 23:16 |
| clarkb | donnyd: yours is likely qcow2? | 23:16 |
| donnyd | correct | 23:16 |
| clarkb | ianw: oh does your list show failures outside of bionic too? | 23:16 |
| donnyd | oh so 13G is the raw size for the cephs | 23:16 |
| fungi | we upload raw to vexxhost because boot from volume | 23:17 |
| clarkb | donnyd: its actually 17GB | 23:17 |
| ianw | clarkb: hrmmm, hang on, that might be *all* launch attempts. let me fiddle the grep ... | 23:17 |
| clarkb | donnyd: which is why I suspect that is the problem | 23:17 |
| fungi | and also if memory serves, because the on-the-fly conversion to raw via glance tasks was... tasking vexxhost's infrastructure | 23:17 |
| mnaser | yes, i remember that, very well | 23:17 |
| mnaser | i was going to say we technically could go back to qcow2 | 23:18 |
| mnaser | because those new systems have local storage included + bfv if needed | 23:18 |
| donnyd | I was literally just about to ask why not have it convert on the other end | 23:18 |
| ianw | no i think it's right | 23:18 |
| donnyd | but I guess that has already been done before | 23:18 |
| ianw | cat launcher-debug.log | grep 'Launch attempt ' | awk '{print $8}' | sed 's/]//' | sort | uniq > bad-launch.txt ... gets me a list of failed launch attempt id's | 23:18 |
| clarkb | mnaser: clarkb-test1 does not ping and console log show shows no console log so I expect it has failed similarly | 23:18 |
| clarkb | ianw: in that case we've either corrupted all uploads or its something else | 23:18 |
| mnaser | clarkb: yeah, even opening novnc console shows a "no hard disk found" | 23:18 |
| ianw | then the above command pulls on the vexxhots-ca-ymq-1 ones | 23:19 |
| fungi | clarkb: likely due to most of its bytes missing | 23:19 |
| donnyd | those pesky bits and their need to be included | 23:19 |
| mnaser | the nova build log really doesn't seem unhappy at all, unless the image download just broke out early | 23:19 |
| donnyd | do you have the newest version of the bionic image mnaser ? | 23:20 |
| ianw | (btw the OE mirror updated, but getting the sshfp records automatically still remains annoying) | 23:20 |
| mnaser | donnyd: the opendev bionic image? i'm not sure | 23:20 |
| mnaser | but using our images work just fine and other vms in the cloud are launching just fine | 23:20 |
| mnaser | anyways, we've *confirmed* that the ubuntu image is not clean | 23:21 |
| mnaser | perhaps the others are not either, so maybe we can start with that | 23:21 |
| mnaser | oh you know what, let me check something | 23:21 |
| fungi | as clarkb said, if we delete the uploads via nodepool's rpc client, then it should reupload (presumed good) copies | 23:21 |
| donnyd | https://www.irccloud.com/pastebin/hKdVbrb5/ | 23:22 |
| ianw | i have windows open so lmn an i can delete images via nodepool | 23:22 |
| fungi | yeah, maybe once mnaser double-checks whatever it is he's double-checking | 23:22 |
| donnyd | fwiw I had nodepool try to upload 322 images last night | 23:23 |
| donnyd | so maybe there is something there | 23:23 |
| clarkb | donnyd: it will try repeatedly until it has success | 23:23 |
| clarkb | donnyd: I expect it thought each one failed | 23:23 |
| donnyd | clarkb: these were all different names | 23:23 |
| clarkb | donnyd: yes the name is based on when it uploads to you, not the source name | 23:24 |
| donnyd | so it seems like it may have tried to upload every image it has ever built | 23:24 |
| clarkb | no | 23:24 |
| mnaser | ok so the base image is 13G for that disk | 23:25 |
| clarkb | we build one image with a name based on a serial counter: ubuntu-bionic-0000001.qcow2. Then we upload that to each provider as ubuntu-bionic-$epochtime based on when the upload starts | 23:25 |
| donnyd | there is a great need for a sarcasm font | 23:25 |
| clarkb | donnyd: heh. Anyway I think it tried to upload eg 0000001.qcow2 322 times because the first 321 failed | 23:25 |
| mnaser | ianw: please delete it and lets se what happens | 23:25 |
| clarkb | donnyd: we should look into it but I expect they ar eseparate issues | 23:25 |
| mnaser | it certainly seems the wrong size | 23:25 |
| mnaser | we know _that_ is broken | 23:26 |
| ianw | | 0000114333 | 0000000001 | vexxhost-ca-ymq-1 | ubuntu-bionic | ubuntu-bionic-1596656540 | 05fbc2ad-8aa6-4cd6-bd2b-eee942034cf9 | ready | 00:02:09:09 | | 23:26 |
| mnaser | uh | 23:27 |
| mnaser | are you saying there is a vm that went up? | 23:27 |
| ianw | no sorry that's the image i will delete | 23:27 |
| clarkb | ianw: yes that image looks correct to me | 23:27 |
| mnaser | oh, yes, fair :) | 23:27 |
| mnaser | yes, that is the image | 23:27 |
| clarkb | donnyd: 0000114332 | 0000000118 | openedge-us-east <- that says image 0000114332 was uploaded 118 times to open edge | 23:27 |
| clarkb | donnyd: the 118th succeeded so it stopped | 23:27 |
| donnyd | Ah I see | 23:27 |
| donnyd | probably from my DB being busted last night then | 23:28 |
| clarkb | donnyd: what we might want to try is a backoff | 23:28 |
| clarkb | donnyd: I think right now it retries immediately | 23:28 |
| clarkb | but we could do exponential backoff until some reasonable period (one hour?) | 23:28 |
| clarkb | corvus: ^ that may interest you specifically nodepool's insistnence on reuploading immediately | 23:29 |
| ianw | ok, vexxhost bionic image deleting | 23:29 |
| donnyd | clarkb: I am happy with the pummelings nodepool issues TBH - I want to know if something doesn't work right and being kind to a cloud only give one false hope | 23:30 |
| clarkb | donnyd: ok :) I think it is good feedback that if the first 10 fail maybe the 11th will too and we can slow down | 23:30 |
| donnyd | its probably not a bad idea | 23:31 |
| ianw | ok, vexxhost is showing two images uploading, a xenial one and a buster one | 23:32 |
| donnyd | ianw: hopefully the mirror is going a little better this time around | 23:32 |
| ianw | | 0000118348 | 0000000001 | vexxhost-ca-ymq-1 | ubuntu-xenial | None | None | uploading | 00:04:11:34 | | 23:32 |
| ianw | donnyd: yep, it's up :) i just need to add it to dns/inventory now | 23:32 |
| ianw | | 0000145461 | 0000000001 | vexxhost-ca-ymq-1 | debian-buster | None | None | uploading | 00:00:48:15 | | 23:32 |
| ianw | mnaser: do you see those in flight? ^ | 23:33 |
| mnaser | unfortunately with no id it's kinda hard to identify anything | 23:33 |
| ianw | hrm, ok | 23:34 |
| ianw | first thing we should be able to see if the old bionic image is booting i guess | 23:34 |
| donnyd | ianw: I am going to pop out and do that thing were I sit on my couch and stare at the TV. Is there anything else I can do for now before I make my way to the living room | 23:35 |
| ianw | donnyd: no, thank you! :) i'll get it into our systems and then we should be gtg | 23:35 |
| mnaser | ho boy | 23:36 |
| mnaser | `2020-08-05 23:28:58.500 11 WARNING glance.api.v2.images [req-84af7fef-cba3-48bb-bc7d-80026f95908d de81838458254d87a9ef66cc89e22308 86bbbcfa8ad043109d2d7af530225c72 - default default] After upload to backend, deletion of staged image data has failed because it cannot be found at /tmp/staging//05fbc2ad-8aa6-4cd6-bd2b-eee942034cf9` | 23:36 |
| fungi | eww | 23:37 |
| mnaser | is this glance staging image uploads | 23:38 |
| mnaser | https://github.com/openstack/glance/blob/783fa72f481d68962509e708585fea4c163d5bf4/glance/common/config.py#L530-L555 | 23:39 |
| mnaser | are we by any chance trying to import images | 23:39 |
| clarkb | we're doing whatever the code that was shade does in openstacksdk | 23:40 |
| clarkb | I think its the v2 post | 23:40 |
| clarkb | openstack.connection.Connection.create_image() is what we call | 23:41 |
| clarkb | I always get lost in sdk | 23:42 |
| openstackgerrit | Ian Wienand proposed opendev/system-config master: Add OE mirror to inventory https://review.opendev.org/744999 | 23:43 |
| *** yoctozepto3 has joined #opendev | 23:44 | |
| mnaser | ok found a potential issue with image upload si guess | 23:44 |
| mnaser | "OSError: timeout during read(8388608) on wsgi.input" | 23:44 |
| *** yoctozepto has quit IRC | 23:45 | |
| *** yoctozepto3 is now known as yoctozepto | 23:45 | |
| clarkb | mnaser: the condition in sdk seems to be if filename or data then self._upload_image | 23:48 |
| clarkb | I think that implies to me that it really shouldn't be using import | 23:48 |
| clarkb | (because our images are local files so it will do the direct upload) | 23:48 |
| mnaser | clarkb: i think it is direct upload, but it seems the glance excpetion handler always calls unstage | 23:48 |
| mnaser | which tries to rm the staged file, even if its not being imported | 23:48 |
| mnaser | so that's more of a fallout | 23:48 |
| clarkb | gotcha and potentially a glance bug? | 23:48 |
| mnaser | maybe -- haven't grasped the whole thing, but i do see some wsgi save timeouts | 23:49 |
| mnaser | Failed to upload image data due to internal error: OSError: timeout during read(8388608) on wsgi.input | 23:49 |
| openstackgerrit | Ian Wienand proposed opendev/zone-opendev.org master: Add replacement OE mirror https://review.opendev.org/745000 | 23:50 |
| clarkb | wow we have 4 different ssh host key types? | 23:50 |
| mnaser | the upload time does correspond to the same failure time though | 23:51 |
| mnaser | so likely that | 23:51 |
| ianw | clarkb: interesting actually, that's with ssh-keygen -r on the host, the others i generated via -D ... i wonder if it's different external v internal | 23:57 |
| ianw | the others are missing "2" | 23:58 |
| clarkb | could that be old dsa keys that remote queries just ignore? | 23:58 |
Generated by irclog2html.py 2.17.2 by Marius Gedminas - find it at https://mg.pov.lt/irclog2html/!
{kind=link}
{kind=link}