| *** tosky has quit IRC | 00:02 | |
| *** dingyichen has joined #openstack-infra | 00:03 | |
| *** dychen has quit IRC | 00:03 | |
| dansmith | clarkb: am I wrong that running unit and functional tests on multiple python versions on every patch is maybe contributing to why queue times are so long lately? | 00:09 |
|---|---|---|
| dansmith | don't those all consume a worker for almost as much time during setup as actually running? | 00:10 |
| dansmith | today nova is running py36,38,39 for unit and 38,39 for functional which seems a little much | 00:10 |
| dansmith | and also, couldn't we combine like py38 with cover and maybe even pep8 to make those all run on one worker and avoid setup time? | 00:11 |
| dansmith | yeah, 15m to run tests, but ~30m for the job | 00:17 |
| dansmith | (for unit. | 00:17 |
| *** dciabrin_ has quit IRC | 00:17 | |
| dansmith | 9m to run 2m of pep8 | 00:17 |
| dansmith | 15m to run 8m of cover | 00:18 |
| fungi | the devstack jobs take many times longer, and some of them occupy multiple nodes | 00:20 |
| dansmith | 15+2+8=25 minutes of actual runtime, vs 55 minutes of "cpu time" to run them separate I think | 00:21 |
| *** lxkong0 has joined #openstack-infra | 00:21 | |
| fungi | so yes reducing job count could help some, but reducing devstack jobs would have more impact than reducing unit test or linting jobs | 00:21 |
| dansmith | yeah I know, I'm just wondering if we're wasting worker time re-setting up a basically identical environment just so we can see each test broken out in the report? | 00:21 |
| dansmith | I really wonder if we need to be running grenade *and* grenade-multinode for example | 00:23 |
| fungi | well, re-setting up an environment which is "nearly identical" to some small percentage of the overall jobs run. we have hundreds of such "not quite the same" environments and trying to maintain pre-set-up copies of all of them would also require a ton of resources (and increase complexity many times over) | 00:23 |
| dansmith | aside from bugs in grenade, I wouldn't think that we're actually missing any coverage on the multinode case | 00:23 |
| fungi | we've already tried to use pre-set-up environments in the past and keeping them maintained ends up being far more work than letting them get created at job runtime, but also makes changes to the environment setup itself testable directly | 00:24 |
| fungi | er, building them at job runtime makes them more directly testable i mean | 00:24 |
| dansmith | fungi: right, but if I make a job run tox -epy38,pep8,cover, those should run all in the same pre-set-up worker and just burn some pip time right? | 00:24 |
| dansmith | fungi: yeah, I'm talking about using a more common base config and running more tox envs in a row on it, not trying to make the image more specifci | 00:25 |
| fungi | they would, though you'll need to go digging in a much larger job log to figure out whether what broke was linting, unit tests or your coverage report | 00:25 |
| dansmith | yeah, I'm okay with that | 00:26 |
| fungi | improving efficiency of the environment setup might be more effective | 00:26 |
| dansmith | I guess that seems like more infra work to me, and thought you were arguing against it just a few lines ago :) | 00:26 |
| fungi | like not installing things the job doesn't need just because it's easier to maintain a single list of dependencies than task-specific dependency sets | 00:26 |
| fungi | nope, talking about job configuration | 00:27 |
| dansmith | I'm just saying, if we're spending 50% of our time booting a "basic ubuntu image" worker to run 2m of something, that seems like a waste just so we can have the jobs called out separately | 00:27 |
| fungi | not infrastructure | 00:27 |
| dansmith | okay, I see.. obviously if we can make the setup time faster then that's good, | 00:27 |
| fungi | we spend on average closer to 30 seconds to boot an ubuntu image i think. job setup spends a lot of time installing things people aren't actually using in their jobs | 00:28 |
| dansmith | but if jamming a few things into the same worker means we don't have to micro-optimize, I dunno.. seems easier | 00:28 |
| fungi | might be, i'm not arguing against trying it | 00:28 |
| fungi | folks already do that with linters in some projects | 00:29 |
| fungi | i've not seen anyone cram linting and unit tests into the same job, but it should be doable | 00:29 |
| dansmith | so, the pep8 job I'm looking at, | 00:29 |
| dansmith | ran pep8 for 2 minutes, and was done with that 5m into the job, but the job took another 4 minutes, presumably to clean up and post logs | 00:29 |
| dansmith | well, I run tox -epy38,pep8 locally a lot.. because the pep8 output is short enough that I can scroll up and see the unit test output above it, even if I have a few lines of pep8 fail | 00:30 |
| dansmith | well, those numbers aren't quite right because it looks like the job start time must not be at time zero in the log, so maybe it's more front-loaded.. about 40s of cleanup after we're done with pep8 | 00:31 |
| dansmith | so I assume that's create and boot time or something, which is part of what would be saved | 00:32 |
| dansmith | anyway, I'm just really worried that we're at an 8h turnaround time on a monday | 00:32 |
| dansmith | and looking at everything we're running in a nova job these days, it seems like we should pare that down | 00:33 |
| fungi | as we've said in the past, the biggest impact you can make on node utilization is to ferret out nondeterministic failures in projects/tests which burn a ton of nodes by having to retest changes and discarding lots of other builds | 00:33 |
| dansmith | sure, and I'm still trying to land such a fix from last week :) | 00:34 |
| dansmith | I definitely continue to push on people to do that, | 00:34 |
| dansmith | but as we noted last week, it sounds like maybe some job configs have grown a little heavy | 00:34 |
| dansmith | clarkb said he wasn't seeing a lot of resets when we had a >24h turnaround time last week | 00:34 |
| fungi | the longer gate queues and the gate failures i see at the moment are for tripleo, yeah | 00:36 |
| fungi | but also zuul's very nearly caught up from earlier today at this point | 00:37 |
| dansmith | fungi: the head of the nova queue is 8h old | 00:37 |
| fungi | we peaked at a backlog of 1.7k nodes and are down to just being 400 behind now | 00:37 |
| dansmith | if tripleo has a lot of fails (and we know they have heavy jobs) we probably also need to focus attention there | 00:38 |
| fungi | in the next hour or so i expect all changes in all pipelines will have node assignments filled | 00:38 |
| fungi | looks like puppet-openstack also just tagged 26 releases | 00:44 |
| fungi | well, "just" nearly three hours ago | 00:45 |
| *** jamesmcarthur has joined #openstack-infra | 00:46 | |
| *** jamesmcarthur has quit IRC | 00:52 | |
| *** JanZerebecki[m] has joined #openstack-infra | 01:17 | |
| *** jamesmcarthur has joined #openstack-infra | 01:19 | |
| *** jamesmcarthur has quit IRC | 01:19 | |
| *** jamesmcarthur has joined #openstack-infra | 01:20 | |
| *** jamesmcarthur has quit IRC | 01:20 | |
| *** jamesmcarthur has joined #openstack-infra | 01:26 | |
| *** jamesmcarthur has quit IRC | 01:57 | |
| *** ysandeep|away is now known as ysandeep | 02:07 | |
| *** jamesmcarthur has joined #openstack-infra | 02:18 | |
| *** jamesmcarthur has quit IRC | 02:23 | |
| *** jamesmcarthur has joined #openstack-infra | 02:23 | |
| *** rcernin has quit IRC | 02:26 | |
| *** jamesmcarthur has quit IRC | 02:29 | |
| *** jamesmcarthur has joined #openstack-infra | 02:33 | |
| *** jamesmcarthur has quit IRC | 02:34 | |
| *** rcernin has joined #openstack-infra | 02:42 | |
| *** rcernin has quit IRC | 02:44 | |
| *** rcernin has joined #openstack-infra | 02:44 | |
| *** jamesmcarthur has joined #openstack-infra | 02:56 | |
| *** verdurin has quit IRC | 03:02 | |
| *** verdurin has joined #openstack-infra | 03:07 | |
| *** jhesketh_ has joined #openstack-infra | 03:40 | |
| *** jhesketh has quit IRC | 03:41 | |
| *** jhesketh_ is now known as jhesketh | 03:43 | |
| *** lxkong0 is now known as lxkong | 03:47 | |
| *** zzzeek has quit IRC | 03:48 | |
| *** zzzeek has joined #openstack-infra | 03:51 | |
| *** ricolin has joined #openstack-infra | 03:54 | |
| *** ysandeep is now known as ysandeep|pto | 03:55 | |
| *** lbragstad has quit IRC | 04:16 | |
| *** ykarel has joined #openstack-infra | 04:18 | |
| *** zzzeek has quit IRC | 04:33 | |
| *** zzzeek has joined #openstack-infra | 04:35 | |
| *** guillaumec has quit IRC | 05:40 | |
| *** guillaumec has joined #openstack-infra | 05:44 | |
| ykarel | frickler, hberaud fyi tarballs are available and our jobs passing now | 06:00 |
| *** ykarel_ has joined #openstack-infra | 06:16 | |
| *** ykarel has quit IRC | 06:19 | |
| *** vishalmanchanda has joined #openstack-infra | 06:20 | |
| *** ykarel_ is now known as ykarel | 06:29 | |
| *** sboyron has joined #openstack-infra | 06:33 | |
| *** jamesmcarthur has quit IRC | 07:06 | |
| *** amoralej|off is now known as amoralej | 07:15 | |
| *** rcernin has quit IRC | 07:19 | |
| *** xek has joined #openstack-infra | 07:22 | |
| *** ralonsoh has joined #openstack-infra | 07:27 | |
| *** lpetrut has joined #openstack-infra | 07:39 | |
| hberaud | ykarel: ack, thanks for the heads up | 07:41 |
| *** nightmare_unreal has joined #openstack-infra | 07:44 | |
| *** eolivare has joined #openstack-infra | 07:47 | |
| *** slaweq has joined #openstack-infra | 07:48 | |
| *** yamamoto has quit IRC | 07:53 | |
| *** jcapitao has joined #openstack-infra | 07:57 | |
| *** dciabrin_ has joined #openstack-infra | 08:00 | |
| *** dchen has quit IRC | 08:01 | |
| *** rpittau|afk is now known as rpittau | 08:07 | |
| *** yamamoto has joined #openstack-infra | 08:11 | |
| *** andrewbonney has joined #openstack-infra | 08:13 | |
| *** zzzeek has quit IRC | 08:14 | |
| *** zzzeek has joined #openstack-infra | 08:16 | |
| *** hashar has joined #openstack-infra | 08:22 | |
| *** tosky has joined #openstack-infra | 08:39 | |
| *** gfidente has joined #openstack-infra | 08:40 | |
| *** jpena|off is now known as jpena | 08:58 | |
| *** lucasagomes has joined #openstack-infra | 09:04 | |
| *** jamesmcarthur has joined #openstack-infra | 09:06 | |
| *** sboyron has quit IRC | 09:06 | |
| *** sboyron_ has joined #openstack-infra | 09:06 | |
| *** jamesmcarthur has quit IRC | 09:11 | |
| *** ricolin has quit IRC | 09:12 | |
| *** ricolin has joined #openstack-infra | 09:13 | |
| *** ociuhandu has joined #openstack-infra | 09:15 | |
| amoralej | hi, may i get some attention on https://review.opendev.org/c/zuul/zuul-jobs/+/771105/ and https://review.opendev.org/c/zuul/zuul-jobs/+/770815 ? | 09:32 |
| amoralej | we need it to get proper repos configured in centos8 stream jobs | 09:33 |
| *** rcernin has joined #openstack-infra | 09:43 | |
| *** sboyron has joined #openstack-infra | 09:43 | |
| *** sboyron_ has quit IRC | 09:43 | |
| *** derekh has joined #openstack-infra | 09:43 | |
| openstackgerrit | Hervé Beraud proposed openstack/project-config master: Adding irc notification for missing oslo projects https://review.opendev.org/c/openstack/project-config/+/771392 | 09:49 |
| *** hashar is now known as hasharOut | 09:59 | |
| *** sboyron_ has joined #openstack-infra | 10:05 | |
| *** sboyron has quit IRC | 10:08 | |
| *** ociuhandu has quit IRC | 10:19 | |
| *** ociuhandu has joined #openstack-infra | 10:24 | |
| *** ociuhandu has quit IRC | 10:24 | |
| *** ociuhandu has joined #openstack-infra | 10:25 | |
| *** rcernin has quit IRC | 10:28 | |
| *** ociuhandu has quit IRC | 10:29 | |
| *** ociuhandu has joined #openstack-infra | 10:58 | |
| *** ociuhandu has quit IRC | 11:12 | |
| *** ociuhandu has joined #openstack-infra | 11:12 | |
| *** rcernin has joined #openstack-infra | 11:13 | |
| *** ysandeep|pto is now known as ysandeep | 11:14 | |
| *** ociuhandu has quit IRC | 11:17 | |
| *** jcapitao is now known as jcapitao_lunch | 11:26 | |
| geguileo | amoralej: is the second patch going to fix the centos-8 jobs that are trying https://mirror.bhs1.ovh.opendev.org/wheel/centos-8.3-x86_64 instead of the right one? | 11:27 |
| geguileo | amoralej: ignore me, it's not, that patch is for stream | 11:27 |
| geguileo | and I'm talking about centos-8 | 11:27 |
| amoralej | geguileo, yes, it's probably a different issue | 11:28 |
| geguileo | amoralej: maybe you can point me in the right direction then... | 11:30 |
| geguileo | centos-8 nodeset is using an incorrect wheel mirror which is making some jobs fails... | 11:31 |
| geguileo | it's trying https://mirror.bhs1.ovh.opendev.org/wheel/centos-8.3-x86_64 | 11:31 |
| geguileo | and it should be https://mirror.bhs1.ovh.opendev.org/wheel/centos-8-x86_64 | 11:31 |
| amoralej | geguileo, can you point me to a failing job? | 11:33 |
| geguileo | amoralej: https://zuul.opendev.org/t/openstack/build/6d6fb0dde981476ab9981fe80a093bf1 | 11:34 |
| geguileo | amoralej: I think the problem is the definition of "wheel_mirror" that uses {{ ansible_distribution_version }} instead of just the major version... | 11:35 |
| geguileo | because we don't have a default in roles/configure-mirrors/vars/CentOS.yaml | 11:37 |
| *** rcernin has quit IRC | 11:37 | |
| amoralej | yes, looks like so | 11:37 |
| geguileo | do you know if all pip URLs use centos-8-x86_64 or if some use centos-8.3-x86_64 format? | 11:41 |
| amoralej | geguileo, cuiously it doesn't fail in centos7.9 jobs | 11:41 |
| amoralej | even if the wheels dir does not exist | 11:41 |
| amoralej | geguileo, i have no idea tbh | 11:41 |
| geguileo | amoralej: maybe because we are "lucky" and this bug is affecting that ansible version... https://github.com/ansible/ansible/issues/50141 | 11:41 |
| geguileo | which reports 7 when it should be saying 7.9 | 11:42 |
| amoralej | no | 11:42 |
| amoralej | i see it's using 7.9 | 11:42 |
| amoralej | in fact in a centos8 run from some days ago it worked | 11:42 |
| amoralej | https://zuul.opendev.org/t/openstack/build/1d67a1289d3d417188d13a5f4451c60e/console | 11:42 |
| geguileo | mmmmm, and what's the wheel mirror used to build alembic? | 11:42 |
| geguileo | amoralej: on that job alembic was already present in the system | 11:43 |
| amoralej | yes | 11:44 |
| amoralej | that's what i'm seeing | 11:44 |
| geguileo | so it didn't have to build it... | 11:44 |
| amoralej | anyway it's clear that the mirror url is wrong | 11:45 |
| geguileo | amoralej: did you get to see the wheel mirror URL anywhere on that job? | 11:45 |
| *** yamamoto has quit IRC | 11:45 | |
| amoralej | it's what you pointed | 11:45 |
| amoralej | in configure-mirrors/defaults/main.yaml | 11:46 |
| *** yamamoto has joined #openstack-infra | 11:46 | |
| *** yamamoto has quit IRC | 11:46 | |
| geguileo | amoralej: yeah, but I meant the one actually being used by that job | 11:46 |
| geguileo | as in seen it in the logs | 11:46 |
| *** yamamoto has joined #openstack-infra | 11:47 | |
| geguileo | found it (I think) | 11:47 |
| amoralej | it needs to be overriden in CentOS.yaml | 11:47 |
| *** yamamoto has quit IRC | 11:47 | |
| geguileo | amoralej: that's what I'd like to confirm... | 11:48 |
| amoralej | geguileo, i think it's in https://opendev.org/zuul/zuul-jobs/src/branch/master/roles/configure-mirrors/vars/CentOS.yaml | 11:48 |
| geguileo | amoralej: yeah, that's where I need to add it | 11:48 |
| *** yamamoto has joined #openstack-infra | 11:48 | |
| *** yamamoto has quit IRC | 11:48 | |
| geguileo | amoralej: but I don't want to break 7.9 jobs just to fix 8 jobs | 11:48 |
| *** yamamoto has joined #openstack-infra | 11:48 | |
| geguileo | XD | 11:48 |
| amoralej | it loads in https://opendev.org/zuul/zuul-jobs/src/branch/master/roles/configure-mirrors/tasks/mirror.yaml#L6 | 11:49 |
| amoralej | well, you may even create a CentOS-8.yaml | 11:49 |
| amoralej | if you prefer | 11:49 |
| *** yamamoto has quit IRC | 11:49 | |
| amoralej | but i'd say it should not break centos7 | 11:49 |
| geguileo | amoralej: well, we either have the centos7 jobs with the wrong wheel mirrors now, or it could break them | 11:50 |
| amoralej | it has wrong mirror url | 11:51 |
| geguileo | amoralej: ok, will send the fix now | 11:52 |
| amoralej | check in https://zuul.opendev.org/t/openstack/build/b221eba358a5443990f6fd5809bde2b7 | 11:52 |
| geguileo | amoralej: yup, thanks | 11:53 |
| *** ramishra has quit IRC | 11:55 | |
| *** ociuhandu has joined #openstack-infra | 11:57 | |
| *** ramishra has joined #openstack-infra | 11:57 | |
| *** ricolin has quit IRC | 11:57 | |
| *** dpawlik has quit IRC | 11:57 | |
| *** logan- has quit IRC | 11:57 | |
| *** paladox has quit IRC | 11:57 | |
| *** fresta has quit IRC | 11:57 | |
| *** lifeless has quit IRC | 11:57 | |
| *** abhishekk has quit IRC | 11:57 | |
| *** gryf has quit IRC | 11:57 | |
| *** DinaBelova has quit IRC | 11:57 | |
| *** markmcclain has quit IRC | 11:57 | |
| *** paladox has joined #openstack-infra | 11:57 | |
| *** fresta has joined #openstack-infra | 11:58 | |
| *** ricolin has joined #openstack-infra | 11:58 | |
| *** lpetrut_ has joined #openstack-infra | 11:58 | |
| *** lifeless has joined #openstack-infra | 11:58 | |
| *** DinaBelova has joined #openstack-infra | 11:58 | |
| *** markmcclain has joined #openstack-infra | 11:58 | |
| *** abhishekk has joined #openstack-infra | 11:59 | |
| *** gryf has joined #openstack-infra | 11:59 | |
| *** logan- has joined #openstack-infra | 12:00 | |
| *** lpetrut has quit IRC | 12:01 | |
| *** ociuhandu has quit IRC | 12:10 | |
| *** ociuhandu has joined #openstack-infra | 12:13 | |
| *** eolivare_ has joined #openstack-infra | 12:14 | |
| *** dpawlik has joined #openstack-infra | 12:15 | |
| *** eolivare has quit IRC | 12:16 | |
| *** ociuhandu has quit IRC | 12:18 | |
| *** ajitha_ has joined #openstack-infra | 12:23 | |
| *** ociuhandu has joined #openstack-infra | 12:29 | |
| *** ociuhandu has quit IRC | 12:30 | |
| *** ociuhandu has joined #openstack-infra | 12:32 | |
| *** jpena is now known as jpena|lunch | 12:34 | |
| *** ajitha_ is now known as ajitha | 12:34 | |
| *** jcapitao_lunch is now known as jcapitao | 12:44 | |
| *** hasharOut is now known as hashar | 12:45 | |
| *** ttx has quit IRC | 12:51 | |
| *** rlandy has joined #openstack-infra | 12:51 | |
| *** eolivare_ has quit IRC | 12:53 | |
| *** yamamoto has joined #openstack-infra | 12:58 | |
| *** amoralej is now known as amoralej|lunch | 12:59 | |
| *** ykarel has quit IRC | 13:01 | |
| *** ttx has joined #openstack-infra | 13:04 | |
| openstackgerrit | Luigi Toscano proposed openstack/project-config master: cursive: prepare to move the jobs in-tree https://review.opendev.org/c/openstack/project-config/+/771443 | 13:12 |
| *** ykarel has joined #openstack-infra | 13:24 | |
| *** jamesmcarthur has joined #openstack-infra | 13:26 | |
| *** eolivare_ has joined #openstack-infra | 13:26 | |
| *** jpena|lunch is now known as jpena | 13:34 | |
| *** lbragstad has joined #openstack-infra | 13:37 | |
| *** zul has joined #openstack-infra | 13:40 | |
| *** yamamoto has quit IRC | 13:42 | |
| *** _erlon_ has joined #openstack-infra | 13:49 | |
| *** amoralej|lunch is now known as amoralej | 13:58 | |
| *** yamamoto has joined #openstack-infra | 14:15 | |
| *** yamamoto has quit IRC | 14:26 | |
| *** slittle1 has quit IRC | 14:32 | |
| *** akantek has joined #openstack-infra | 14:33 | |
| *** akantek has quit IRC | 14:34 | |
| *** dave-mccowan has quit IRC | 14:38 | |
| *** rcernin has joined #openstack-infra | 14:42 | |
| *** rcernin has quit IRC | 15:01 | |
| *** derekh has quit IRC | 15:20 | |
| *** derekh has joined #openstack-infra | 15:20 | |
| openstackgerrit | Merged openstack/project-config master: Add PTP Notification app to StarlingX https://review.opendev.org/c/openstack/project-config/+/771235 | 15:22 |
| *** gryf has quit IRC | 15:26 | |
| *** ociuhandu has quit IRC | 15:27 | |
| *** hashar is now known as hasharKids | 15:28 | |
| *** gryf has joined #openstack-infra | 15:31 | |
| *** sshnaidm|ruck is now known as sshnaidm|afk | 15:37 | |
| *** ysandeep is now known as ysandeep|dinner | 15:37 | |
| clarkb | dansmith: fungi ya when we haev looked at numbers in the past the long running multinode jobs so completely dwarf the other jobs that trying to optmize linting or even unittests for projects won't have a large effect | 15:42 |
| *** dklyle has joined #openstack-infra | 15:43 | |
| dansmith | clarkb: okay but, if every nova review is running five jobs that it doesn't need, even if they're small, I would think that would add up | 15:43 |
| fungi | we do have data we can use to attempt to calculate how many node-hours we spend on various jobs and per project | 15:44 |
| dansmith | clarkb: I know it would be zuul changes and maybe some more noise, but have we ever considered batching the jobs into long and short? so that we get a quicker report of unit, functional, linting and then a later report of the heavy stuff? | 15:45 |
| fungi | which would probably lead to a more useful analysis, and less abstract conjecture | 15:45 |
| clarkb | dansmith: it is >0 but not significant. Last time we ran numbers tripleo alone was like 35% or something like that of resource usage and they don't do linting and unittests really | 15:45 |
| clarkb | its all their 3 hour multiple jobs that quickly dominate | 15:45 |
| clarkb | I can see if I can run that script again today | 15:46 |
| clarkb | I think it also outputs job consumption which helps see it from the linting/unittests vs integration angle | 15:46 |
| *** ysandeep|dinner is now known as ysandeep | 15:47 | |
| dansmith | clarkb: can we figure out some relative stat? like hours per review or something likethat? | 15:47 |
| clarkb | dansmith: yes, we've actually done that. What we found when we tried it is you get a lot more round trips and it doesn't help on the whole | 15:47 |
| fungi | dansmith: some projects do hold longer jobs until their shorter jobs pass, but the down sides to that are 1. you may need additional patchsets when you find out that you have more than one error exposed in different jobs some of which weren't run the first time, and 2. it'll take longer to get a result because the jobs are no longer run in parallel | 15:47 |
| *** zul has quit IRC | 15:47 | |
| dansmith | clarkb: like, I want to compare them against other projects to say "tripleo has half as many patches as nova, but consumes 4x the bandwidth" | 15:48 |
| clarkb | dansmith: you should be able to do that as a derivative from the numbers the existing script prints out | 15:48 |
| dansmith | okay | 15:48 |
| dansmith | clarkb: a while ago we discussed per-project throttling such that 100-patch series in nova didn't swap single-patch glance reviews from getting timely results | 15:50 |
| fungi | yeah, zuul has been doing that for a while now | 15:51 |
| dansmith | is that (a) still happening and (b) do the long serialized jobs defeat that because they use a lot of nodes and run a long time? | 15:51 |
| fungi | yes, a change which runs 20 3-hour multinode jobs gets weighted the same as a change which runs a docs build, from a "fair queuing" perspective | 15:51 |
| dansmith | okay | 15:52 |
| dansmith | and is the fairness across the project level or the git dep chain? | 15:52 |
| dansmith | I ask because I can't tell (by the seat of my pants) that my single-patch glance reviews go any quicker than my nova ones, when there's literally nothing in the queue for glance | 15:53 |
| fungi | it's per project queue, so in check that's basically at the project level, in gate it's at the dependent queue level (but you rarely observe that because the gate pipeline gets top priority anyway) | 15:53 |
| dansmith | ack, okay | 15:53 |
| dansmith | so these long wide heavy jobs must be putting both glance and nova patches so deep into the "not even considered yet" queue that I can't tell | 15:54 |
| fungi | and it doesn't necessarily affect how fast the jobs run, it's just about prioritizing node requests, so if there's a backlog of node requests the projects with fewer changes get their node requests filled sooner | 15:54 |
| dansmith | aye | 15:55 |
| *** ociuhandu has joined #openstack-infra | 15:55 | |
| fungi | from a "fairness" perspective it's far from perfect, but it's the best mechanism we were able to fit to the available data model and control points in the system | 15:57 |
| clarkb | dansmith: http://paste.openstack.org/show/jD6kAP9tHk7PZr2nhv8h/ the aggregation there uses openstack/governance/reference/projects.yaml to decide what is tripleo and neutron and so on | 15:57 |
| dansmith | dear $deity | 15:57 |
| dansmith | tripleo and neutron together use over 50%? | 15:57 |
| clarkb | that shows things in openstack goverance consumed 95.5% of used cpu time. 30% of the total was tripleo jobs. 22% neutron and so on | 15:57 |
| clarkb | yes | 15:57 |
| clarkb | note neutron runs tripleo jobs too | 15:58 |
| dansmith | yeah | 15:58 |
| slaweq | clarkb: we just discussed in our ci meeting to move some of those jobs to periodic queue | 15:58 |
| slaweq | I will propose patch in few minutes | 15:58 |
| dansmith | slaweq: ++ | 15:58 |
| dansmith | slaweq: note that nova is 5% on that chart :) | 15:59 |
| clarkb | all openstack-tox-py36 jobs used about 1% of consumed resources | 15:59 |
| dansmith | clarkb: is there number-of-reviews data in that paste that I'm missing? | 15:59 |
| clarkb | so if we say the "lightweight" jobs are maybe 5% total you can optimize that but the dent is tiny | 15:59 |
| clarkb | dansmith: no you need to grab that from gerrit's api | 15:59 |
| clarkb | the date range is in my report and it breaks it down by repo too | 16:00 |
| clarkb | which should be enough to ask gerrit for data (I think fungi may even have a script that does taht bit?) | 16:00 |
| *** ykarel is now known as ykarel|away | 16:00 | |
| *** ociuhandu has quit IRC | 16:01 | |
| *** diablo_rojo has joined #openstack-infra | 16:01 | |
| fungi | https://review.opendev.org/729293 aggregates by git namespace so all of openstack/ gets lumped together, but you could tweak the aggregation (it shards the queries by repo already for better pagination stability) | 16:01 |
| *** sshnaidm|afk is now known as sshnaidm|ruck | 16:03 | |
| *** amoralej is now known as amoralej|off | 16:11 | |
| *** ociuhandu has joined #openstack-infra | 16:11 | |
| *** ykarel|away has quit IRC | 16:17 | |
| *** yamamoto has joined #openstack-infra | 16:26 | |
| *** yamamoto has quit IRC | 16:34 | |
| *** armax has joined #openstack-infra | 16:35 | |
| *** derekh has quit IRC | 16:43 | |
| *** lbragstad_ has joined #openstack-infra | 16:46 | |
| *** lpetrut_ has quit IRC | 16:48 | |
| *** slaweq has quit IRC | 16:48 | |
| *** rlandy_ has joined #openstack-infra | 16:48 | |
| *** slaweq has joined #openstack-infra | 16:49 | |
| *** jamesdenton has quit IRC | 16:49 | |
| *** gryf has quit IRC | 16:49 | |
| *** lbragstad has quit IRC | 16:49 | |
| *** rlandy has quit IRC | 16:49 | |
| *** jamesdenton has joined #openstack-infra | 16:49 | |
| *** rlandy_ is now known as rlandy | 16:50 | |
| *** gryf has joined #openstack-infra | 16:50 | |
| *** lbragstad_ is now known as lbragstad | 16:58 | |
| zbr | i do believe that we could improve the developer experience if we can find a way to priorietize low-resource jobs. | 16:59 |
| clarkb | zuul does already support it, developers can opt into it by modifying their job pipeline graphs | 17:00 |
| zbr | so far we used queues, but these are more of by project. | 17:00 |
| clarkb | I dno't think it will be helpful, but the tool allows it and some are trying it aiui | 17:00 |
| *** lucasagomes has quit IRC | 17:01 | |
| *** jamesmcarthur has quit IRC | 17:03 | |
| *** jamesmcarthur has joined #openstack-infra | 17:03 | |
| *** jcapitao has quit IRC | 17:05 | |
| fungi | prioritizing low-resource jobs wouldn't necessarily get you results any sooner, unless those were all you were running | 17:05 |
| dansmith | fungi: well, that's why I was asking about two batches.. if you're relying on zuul to run pep8 for you then it's not going to help, but if you rely on it to run and find problems with python versions you don't have, then maybe | 17:08 |
| dansmith | fungi: there's also some locality of review, where I'd +2 something I saw pass functional tests and let the gate sort out merging based on whether devstack jobs worked, | 17:09 |
| dansmith | but otherwise, I'll pretty much wait until I see the results, which right now is often "not today" | 17:09 |
| dansmith | my queuing isn't as good as zuul, which means it might be "not until $owner pings me again" | 17:10 |
| zbr | while it is possible for each project to optimize how jobs are triggered (dependencies and fail-fast), there is very little incentive for them to do it mainly because that means "slow yourself down and spend extra effort doing it, for the greater good". | 17:10 |
| dansmith | not the worst thing, but the whole point of this is to make machines improve life for humans :) | 17:10 |
| clarkb | dansmith: yes but at the same time the machiens have a limited set of resources (which seems to only shrink) | 17:11 |
| dansmith | zbr: that's certainly true, but it sounds like some projects obsess over their job optimization more than others, which makes some of us angry :) | 17:11 |
| *** sshnaidm|ruck is now known as sshnaidm|afk | 17:11 | |
| fungi | and an ever shrinking number of people managing them and developing the systems which run on top of them | 17:11 |
| dansmith | clarkb: I assure you I have a limited set of resources | 17:11 |
| clarkb | yes me too | 17:11 |
| clarkb | but I keep getting asked to work miracles :) | 17:11 |
| clarkb | reality is this problem has existed for years | 17:12 |
| dansmith | are you referring to me? | 17:12 |
| clarkb | I've called it out for years | 17:12 |
| clarkb | and no one has really cared until it all melts down and then its too late | 17:12 |
| zbr | if we look at the problem from the CI system point of view, where you want to optimize resource usage and maximize how fast jobs are tests in general, you may want to promote good-players (low resource users). | 17:12 |
| clarkb | dansmith: not just you, but it seems the demands on this team are higher than ever and we're smaller than ever | 17:12 |
| clarkb | zbr: low resources users aren't necessarily "good-players" | 17:12 |
| *** _erlon_ has quit IRC | 17:13 | |
| clarkb | it could be that low resource users allow more bugs in which caues more gate resets in the long run | 17:13 |
| dansmith | clarkb: I'm sorry, I think I've asked you only for help understanding so far in 2021.. if that's asking too much then I'll go away | 17:13 |
| clarkb | dansmith: its not asking too much, its just really difficult to hear a lot of suggestions when we have been asking for help for years and we get the opposite. And that isn't to say you are the problem. Its systemic in the community | 17:14 |
| clarkb | that script was originally written because the TC and otehrs kept accusing new small projects for the queue backups when in reality it was openstack itself (and a small numebr of resource hogs) | 17:15 |
| clarkb | and the timestamp on that file is ~2018 | 17:15 |
| clarkb | I'm just trying to keep the lights on most days anymore | 17:16 |
| *** ociuhandu_ has joined #openstack-infra | 17:16 | |
| clarkb | being able to add features to zuul (or even fix bugs in zuul) seems like a luxury | 17:16 |
| clarkb | another related issue is the swapping in devstack jobs | 17:17 |
| dansmith | clarkb: sorry, I'm missing something.. I can't help with things like cloud quota or giving you warm bodies, all I can help with is either trying to understand, brainstorming other technical improvements, or trying to convince people to tweak/shrink their jobs | 17:17 |
| *** zbr3 has joined #openstack-infra | 17:18 | |
| clarkb | dansmith: yes, I think the ball has been in openstack's court for fixing these queue issues for several years now | 17:18 |
| dansmith | clarkb: if you've interpreted the brainstorming as zuul feature demands, then I'm really sorry and clearly communicated poorly | 17:18 |
| clarkb | openstack runs a number of large innefficiencies in its CI jobs. Devstack being central to a number of them. For example you can cut devstack spin up time by around at least a half simply by not using osc and writing a python script to do the keystone setup (because osc startup time is bad and it doesn't cache tokens) | 17:19 |
| fungi | to clarify though, we've literally deployed all this with open source software and configured with code reviewed continuously deployed configuration management, much of which is self-testing now, so the things which require privileged access to systems isn't that much | 17:19 |
| *** ociuhandu has quit IRC | 17:19 | |
| clarkb | Devstack also swaps in many of its jobs which create performance issues as well | 17:19 |
| clarkb | Er as well as stability issues | 17:19 |
| *** zbr has quit IRC | 17:20 | |
| *** zbr3 is now known as zbr | 17:20 | |
| clarkb | tuning the devstack jobs to not swap or even better improving openstack's memory consumption in its services would go a long way for making the jobs run quicker and also be more reliable | 17:20 |
| *** ociuhandu_ has quit IRC | 17:20 | |
| clarkb | the tripleo side of things is harder for me to characterize because it changes often and uses tools I'm less familar with, but I expect there are similar improvements that can be made there | 17:20 |
| fungi | putting openstack on a diet and revisiting devstack's and tripleo's frameworks with an eye toward efficiency would certainly have a huge impact compared to messing around with reordering jobs or trying to cram two lightweight jobs into one | 17:21 |
| clarkb | I did a poc for the osc replacement in devstack but was told it was too complicated for uesrs | 17:21 |
| clarkb | so instead we spend about 10-15 minutes per devsatck job running osc instead of like 20 seconds for a python script | 17:21 |
| fungi | well, also the qa team didn't like that it wasn't using all separate openstackclient commands | 17:22 |
| fungi | daemon mode osc would have also probably had similar performance impact, but that never got completed | 17:22 |
| clarkb | (and again I don't think its any one person's fault, but it seems there are systemic issues that specifically oppose solving these problems on the job end and instead we tend to prefer pushing that to the hosting providers) | 17:24 |
| clarkb | but we've largely run out of our ability to scale up the hosting provider | 17:24 |
| zbr | there is one aspect that affects our performance: number of jobs X random-failure rate. Projects with lots of jobs are far more likely to fail at agate, is just statistics. | 17:24 |
| zbr | Assuming a 2% random failure rate, if you have 15 jobs this translates to ~26% change of failing. | 17:27 |
| zbr | sadly nobody was able to count the real number of random failures, but i guess that we could compute it based on "successful rechecks". | 17:29 |
| clarkb | zbr: yes, that coupled with gate states being dependent on their parents is what makes gate resets so painful | 17:29 |
| clarkb | but also "random failures" tend to be pretty low in historical tracking we've done | 17:29 |
| clarkb | a significant portion of failures represent actual bugs somewhere | 17:30 |
| clarkb | gratned those may be in places we don't have any hoep of fixing (like nested virt crashing due to aprticular combos of kernels in a provider or provider reusing an ip address improperly) | 17:30 |
| *** ociuhandu has joined #openstack-infra | 17:31 | |
| *** jamesmcarthur has quit IRC | 17:31 | |
| *** jamesmcarthur has joined #openstack-infra | 17:32 | |
| clarkb | dansmith: interpreting those things as zuul feature deamnds is likely my personal bias because it seems any time I push on improving the job side the response is no we need to change $zuul thing. I'll try to view these issues with less of that bias | 17:35 |
| *** ociuhandu has quit IRC | 17:35 | |
| dansmith | clarkb: sorry man, really (really) just trying to come up with ideas | 17:36 |
| dansmith | I just fixed an OOM in tempest (yes actually tempest) the other day, trying to chase down stability things to make things better | 17:37 |
| *** jamesmcarthur has quit IRC | 17:37 | |
| dansmith | been messing around with something in devstack today to address osc latency | 17:37 |
| *** rlandy is now known as rlandy|brb | 17:37 | |
| dansmith | I doubt I could really make complex changes to zuul in a reasonable amount of time, | 17:38 |
| *** jamesmcarthur has joined #openstack-infra | 17:38 | |
| dansmith | but in a lot of cases, I don't know what I don't know (like if we're still fair queuing across projects) so I was just asking | 17:38 |
| dansmith | fwiw, I too feel like the cadre of people that care about the infra are all gone | 17:39 |
| dansmith | so it's hard to continue to care instead of just making sure my shit is tight with local testing | 17:39 |
| * fungi is still here ;) | 17:40 | |
| *** hamalq has joined #openstack-infra | 17:40 | |
| dansmith | fungi: yeah I mean people on projects who care to spend time working on non-project infra, common infra, or understanding infra issues to make changes in their projects | 17:40 |
| fungi | but yeah, we've lost sdague, matt, second matt... :( | 17:40 |
| dansmith | fungi: really glad you're still here tho :) | 17:41 |
| dansmith | right, they were always better than me anyway | 17:41 |
| fungi | melwitt has been doing great stuff lately in that vein | 17:41 |
| *** jamesmcarthur has quit IRC | 17:43 | |
| *** gfidente is now known as gfidente|afk | 17:43 | |
| clarkb | dansmith: re the osc thing, is that via improving osc startup time and or token reuse? Those seemed to be the big reasons why osc was slow when I looked in the past, but both were somewhat complicated to address. Startup time because python entrypoint libs and tokens due to security concerns | 17:44 |
| dansmith | clarkb: well, neither and more crazy.. trying to just make devstack less single-threaded, | 17:45 |
| dansmith | but maybe that'll make too much memory pressure | 17:45 |
| clarkb | dansmith: oh interesting | 17:45 |
| fungi | i get the impression the memory pressure in those jobs is more in the tempest phase, so devstack setup may benefit from greater parallelism | 17:46 |
| *** d34dh0r53 has quit IRC | 17:47 | |
| clarkb | fungi: yes I think that is the case. Basically it is the use of the cloud that balloons the memory use | 17:47 |
| dansmith | ack | 17:47 |
| dansmith | so I was toying with being able to start named jobs async, and then say "okay if you get to here make sure $future is done" | 17:48 |
| dansmith | parallelizing the init_project parts for example | 17:48 |
| dansmith | and also the creation of service accounts as another quick example which seems to take EFFING MINUTES | 17:48 |
| fungi | service accounts at the system level? like with adduser command or whatever? | 17:49 |
| dansmith | no keystone service accounts | 17:49 |
| fungi | oh, okay. i wonder how many osc calls that's implemented with | 17:49 |
| dansmith | yeah, it's a lot of osc overhead, but it also seems like some keystone slowness I dunno why | 17:50 |
| *** d34dh0r53 has joined #openstack-infra | 17:50 | |
| dansmith | I also wonder if we couldn't wrap osc shell mode and delegate commands that we run to it | 17:50 |
| dansmith | like I wonder if that would offend anyone, if I could make it work | 17:50 |
| dansmith | ten minutes of osc overhead sounds pretty juicy to me | 17:50 |
| clarkb | dansmith: what my poc did was replace osc for service accounts and catalog bits with a script that used the sdk. That script was then able to cache the token for many requests and have a single startup time | 17:51 |
| clarkb | its been a while but my maths were something like 7 minutes just for keystone setup then a few minutes of other things like create this network and that flavor and so on | 17:51 |
| dansmith | yeah, the keystone stuff is stupid slow | 17:52 |
| dansmith | I'm also parallelizing things like neutron setup (db creation, etc) with things like swift and glance and placement which should be mostly isolated I think | 17:53 |
| dansmith | but the iops may not work out in a cloud worker such that there's benefit | 17:53 |
| zbr | do we have the meeting in one hour? | 17:56 |
| clarkb | yes | 17:56 |
| clarkb | (I sent out an agenda to the list yesterday too if you're curious to see what is on it) | 17:57 |
| * zbr goes out for a while, aiming to return in one hour. | 17:58 | |
| *** eolivare_ has quit IRC | 18:02 | |
| *** jamesmcarthur has joined #openstack-infra | 18:02 | |
| *** gyee has joined #openstack-infra | 18:16 | |
| *** jpena is now known as jpena|off | 18:18 | |
| *** rlandy|brb is now known as rlandy | 18:20 | |
| *** bdodd has quit IRC | 18:23 | |
| *** dtantsur is now known as dtantsur|afk | 18:23 | |
| *** ricolin has quit IRC | 18:34 | |
| *** hasharKids has quit IRC | 18:34 | |
| *** rpittau is now known as rpittau|afk | 18:41 | |
| *** jamesmcarthur has quit IRC | 18:59 | |
| *** jamesmcarthur has joined #openstack-infra | 18:59 | |
| gmann | mnaser: fungi clarkb these project-config changes lgtm and quick to review- https://review.opendev.org/c/openstack/project-config/+/771443 https://review.opendev.org/c/openstack/project-config/+/771392 https://review.opendev.org/c/openstack/project-config/+/771066 https://review.opendev.org/c/openstack/project-config/+/770538 | 19:14 |
| *** nightmare_unreal has quit IRC | 19:14 | |
| fungi | thanks gmann! i guess you're watching the conversation in the opendev meeting | 19:14 |
| fungi | we were just talking about that right now | 19:15 |
| gmann | ah did not see that. | 19:15 |
| gmann | nice | 19:15 |
| fungi | yeah, that's the current topic in the meeting, looking for volunteers for config reviewing | 19:16 |
| gmann | I was checking in #opendev | 19:18 |
| fungi | heh, yeah sorry we have a separate meeting channel but you've found it | 19:22 |
| fungi | we use that for weekly meetings but also scheduled maintenance activities and incident management | 19:22 |
| *** lifeless has quit IRC | 19:27 | |
| *** lifeless has joined #openstack-infra | 19:27 | |
| *** andrewbonney has quit IRC | 19:42 | |
| *** slaweq has quit IRC | 19:43 | |
| *** ajitha has quit IRC | 20:01 | |
| *** Jeffrey4l has quit IRC | 20:04 | |
| *** openstackgerrit has quit IRC | 20:12 | |
| *** Jeffrey4l has joined #openstack-infra | 20:13 | |
| *** zbr5 has joined #openstack-infra | 20:14 | |
| *** zbr has quit IRC | 20:16 | |
| *** zbr5 is now known as zbr | 20:16 | |
| *** bdodd has joined #openstack-infra | 20:29 | |
| *** yamamoto has joined #openstack-infra | 20:32 | |
| *** stevebaker has quit IRC | 20:35 | |
| *** yamamoto has quit IRC | 20:36 | |
| *** vishalmanchanda has quit IRC | 20:39 | |
| *** Jeffrey4l has quit IRC | 20:50 | |
| *** Jeffrey4l has joined #openstack-infra | 20:51 | |
| *** stevebaker has joined #openstack-infra | 21:03 | |
| *** ociuhandu has joined #openstack-infra | 21:07 | |
| *** harlowja has joined #openstack-infra | 21:14 | |
| *** jamesmcarthur has quit IRC | 21:17 | |
| *** jamesmcarthur has joined #openstack-infra | 21:19 | |
| *** sboyron_ has quit IRC | 21:26 | |
| *** priteau has quit IRC | 21:35 | |
| *** jamesmcarthur has quit IRC | 21:42 | |
| *** xek has quit IRC | 21:44 | |
| *** jamesmcarthur has joined #openstack-infra | 21:46 | |
| *** arne_wiebalck has quit IRC | 21:49 | |
| *** arne_wiebalck has joined #openstack-infra | 21:51 | |
| *** matt_kosut has quit IRC | 22:01 | |
| *** matt_kosut has joined #openstack-infra | 22:02 | |
| *** matt_kosut has quit IRC | 22:07 | |
| *** rcernin has joined #openstack-infra | 22:09 | |
| *** yamamoto has joined #openstack-infra | 22:10 | |
| *** jamesmcarthur has quit IRC | 22:16 | |
| *** jamesmcarthur has joined #openstack-infra | 22:23 | |
| *** iurygregory has quit IRC | 22:28 | |
| *** jamesmcarthur has quit IRC | 22:30 | |
| *** jamesmcarthur has joined #openstack-infra | 22:33 | |
| *** iurygregory has joined #openstack-infra | 22:37 | |
| *** ociuhandu has quit IRC | 22:47 | |
| *** ociuhandu has joined #openstack-infra | 22:47 | |
| *** openstackgerrit has joined #openstack-infra | 22:50 | |
| openstackgerrit | Merged openstack/project-config master: cursive: prepare to move the jobs in-tree https://review.opendev.org/c/openstack/project-config/+/771443 | 22:50 |
| openstackgerrit | Merged openstack/project-config master: Adding irc notification for missing oslo projects https://review.opendev.org/c/openstack/project-config/+/771392 | 22:50 |
| openstackgerrit | Merged openstack/project-config master: Combine acl file for all interop source code repo https://review.opendev.org/c/openstack/project-config/+/771066 | 22:50 |
| openstackgerrit | Merged openstack/project-config master: Move snaps ACL to x https://review.opendev.org/c/openstack/project-config/+/770538 | 22:50 |
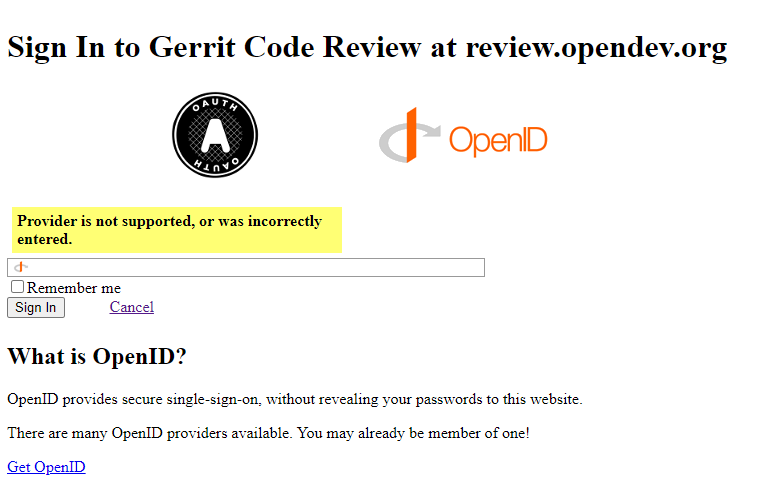
| gagehugo | Is review.opendev.org sign-in now switched to openid? | 22:54 |
| clarkb | gagehugo: its always been openid as far as I know | 22:54 |
| gagehugo | the login page changed, was just wondering | 22:55 |
| *** thogarre has joined #openstack-infra | 22:55 | |
| clarkb | hrm that shouldn't have changed | 22:55 |
| clarkb | itshould take you to the ubuntu one openid login page | 22:55 |
| clarkb | oh except I think I discovered a bug where you can't hit the login button from the diff viewer as the redirects don't work from there? | 22:56 |
| fungi | when you click sign init should take you to https://login.ubuntu.com/ yeah | 22:56 |
| gagehugo | https://usercontent.irccloud-cdn.com/file/dBmWTQfP/image.png | 22:56 |
| fungi | huh, that's the page we've usually seen if login.ubuntu.com is down for some reason | 22:56 |
| gagehugo | ah ok | 22:56 |
| clarkb | fwiw it just worked for me | 22:56 |
| fungi | same here | 22:56 |
| clarkb | so maybe a blip on the remote side | 22:56 |
| gagehugo | someone from our team was having that issue as well so I figured I'd check, thanks! | 22:58 |
| *** snapiri has quit IRC | 22:58 | |
| *** openstackgerrit has quit IRC | 22:59 | |
| clarkb | gagehugo: if it persists I would double check dns resolution and firewall access for login.ubuntu.com | 23:02 |
| gagehugo | ok | 23:02 |
| *** snapiri has joined #openstack-infra | 23:03 | |
| *** snapiri has quit IRC | 23:08 | |
| *** CrayZee has joined #openstack-infra | 23:08 | |
| *** matt_kosut has joined #openstack-infra | 23:17 | |
| *** jamesmcarthur has quit IRC | 23:25 | |
| *** matt_kosut has quit IRC | 23:27 | |
| fungi | yeah, maybe access is being blocked or something | 23:29 |
| fungi | or i suppose it could be a new browser security feature, blocking refresh-redirect to another domain? | 23:30 |
| fungi | something or other breaking openid workflow | 23:30 |
| *** dchen has joined #openstack-infra | 23:31 | |
| *** jamesmcarthur has joined #openstack-infra | 23:43 | |
| *** thogarre has quit IRC | 23:52 | |
| *** ociuhandu has quit IRC | 23:58 | |
| *** ociuhandu has joined #openstack-infra | 23:58 | |
Generated by irclog2html.py 2.17.2 by Marius Gedminas - find it at https://mg.pov.lt/irclog2html/!
{kind=link}