| clarkb | fungi: yup then we should check that the job on the second project sees commit two as master/main/foo and not commit 1 | 00:00 |
|---|---|---|
| fungi | it's probably late in my day to start putting that test together, but i can try tomorrow if nobody beats me to it | 00:01 |
| clarkb | cool I can help with that too and ya dinner should be arriving soon for me | 00:03 |
| clarkb | fungi: it just occured to me that there is an element of luck/randomness involved too as well since it depends on your job being scheduled to an executor that previously ran jobs for the fast forwardable commit before it merged | 00:03 |
| clarkb | if the executor hadn't seen that commit yet then the rev check would fail and the update would happen as expected | 00:03 |
| fungi | yeah, extra luck that lightning struck on the recheck too | 00:04 |
| fungi | i'll recheck it again just to see | 00:04 |
| clarkb | for example ze01 does not have 874d4776eee5ae7c8c15debbb9e943110be299dd and its master ref still points to 99136e1e164baa7b1d9dac4f64c5fb511b813c19 | 00:04 |
| clarkb | if the job lands there I would expect it to update as expected | 00:05 |
| clarkb | the other (third) possible state is master points at 874d4776eee5ae7c8c15debbb9e943110be299dd because a job triggered an update there since 874d4776eee5ae7c8c15debbb9e943110be299dd was not already present | 00:05 |
| clarkb | 02 is like 01 and 03 is like 08 | 00:06 |
| clarkb | 04 is like 08, 05 is like 01, 06 is like 08, 07 is like 08, 09 is like 08, 10 is like 01, 11 is like 01, 12 is like 08 | 00:10 |
| clarkb | none of them are in that third possible state (not sure if that is useful info but there it is) | 00:10 |
| clarkb | fungi: I think you have a 5/12 shot at success given ^ | 00:13 |
| fungi | it got scheduled to ze01 | 00:13 |
| fungi | build is 1088ace4500b4e808b89b079061e8a5a | 00:13 |
| clarkb | master points at your commit there now so it is now in the third state | 00:14 |
| clarkb | (good to confirm that) | 00:14 |
| fungi | 1088ace4500b4e808b89b079061e8a5a | 00:14 |
| fungi | er, wrong buffer | 00:14 |
| fungi | Successfully installed gerritlib-0.10.1.dev1 | 00:14 |
| fungi | so that seems to jive with your theory | 00:14 |
| clarkb | ya, really makes me wonder if we've just missed this issue for a long time or if something I don't understand caused the behavior to change | 00:16 |
| clarkb | because everything else is lining up | 00:17 |
| openstackgerrit | Kenny Ho proposed zuul/zuul master: Allow post playbook to run when run playbook has unreachable result https://review.opendev.org/c/zuul/zuul/+/783986 | 00:23 |
| *** y2kenny has quit IRC | 00:31 | |
| *** hamalq_ has quit IRC | 00:49 | |
| openstackgerrit | Kenny Ho proposed zuul/zuul master: Allow post playbook to run when run playbook has unreachable result https://review.opendev.org/c/zuul/zuul/+/783986 | 00:50 |
| openstackgerrit | Jeremy Stanley proposed zuul/zuul-jobs master: Document algorithm var for remove-build-sshkey https://review.opendev.org/c/zuul/zuul-jobs/+/783988 | 00:56 |
| *** iurygregory has quit IRC | 01:16 | |
| *** iurygregory has joined #zuul | 01:17 | |
| *** iurygregory has quit IRC | 01:18 | |
| *** iurygregory has joined #zuul | 01:18 | |
| *** iurygregory has quit IRC | 02:08 | |
| *** iurygregory has joined #zuul | 02:09 | |
| *** jangutter has joined #zuul | 02:13 | |
| *** jangutter_ has quit IRC | 02:15 | |
| *** evrardjp has quit IRC | 02:33 | |
| *** evrardjp has joined #zuul | 02:33 | |
| *** nhicher has quit IRC | 03:09 | |
| *** fbo has quit IRC | 03:09 | |
| *** nhicher has joined #zuul | 03:13 | |
| *** saneax has joined #zuul | 03:34 | |
| openstackgerrit | Kenny Ho proposed zuul/zuul master: Allow post playbook to run when run playbook has unreachable result https://review.opendev.org/c/zuul/zuul/+/783986 | 03:48 |
| *** ykarel|away has joined #zuul | 04:20 | |
| *** jfoufas1 has joined #zuul | 04:28 | |
| *** vishalmanchanda has joined #zuul | 04:30 | |
| *** ykarel|away is now known as ykarel | 04:39 | |
| *** zbr|rover4 has joined #zuul | 05:04 | |
| *** zbr|rover has quit IRC | 05:06 | |
| *** zbr|rover4 is now known as zbr|rover | 05:06 | |
| openstackgerrit | James E. Blair proposed zuul/zuul-jobs master: Add upload-logs-azure role https://review.opendev.org/c/zuul/zuul-jobs/+/782004 | 05:27 |
| *** jangutter has quit IRC | 06:04 | |
| *** jangutter has joined #zuul | 06:05 | |
| *** ajitha has joined #zuul | 06:11 | |
| *** jcapitao has joined #zuul | 06:27 | |
| *** hashar has joined #zuul | 06:45 | |
| *** harrymichal has joined #zuul | 07:14 | |
| *** harrymichal has quit IRC | 07:17 | |
| openstackgerrit | Tobias Henkel proposed zuul/zuul master: Add spec for enhanced regional executor distribution https://review.opendev.org/c/zuul/zuul/+/663413 | 07:18 |
| *** tosky has joined #zuul | 07:33 | |
| openstackgerrit | Merged zuul/zuul master: Align enqueue/dequeue events with trigger events https://review.opendev.org/c/zuul/zuul/+/783556 | 08:00 |
| *** ykarel has quit IRC | 08:01 | |
| *** dpawlik0 is now known as dpawlik | 08:08 | |
| openstackgerrit | Sorin Sbârnea proposed zuul/zuul master: WIP: Document tox environments https://review.opendev.org/c/zuul/zuul/+/766460 | 08:17 |
| openstackgerrit | Ian Wienand proposed zuul/nodepool master: Bump dib requirement to 3.8.0 https://review.opendev.org/c/zuul/nodepool/+/784026 | 08:29 |
| *** nils has joined #zuul | 08:32 | |
| *** vishalmanchanda has quit IRC | 08:39 | |
| *** ykarel has joined #zuul | 08:43 | |
| *** ykarel is now known as ykarel|lunch | 08:43 | |
| *** jcapitao has quit IRC | 08:51 | |
| *** vishalmanchanda has joined #zuul | 09:11 | |
| *** jcapitao has joined #zuul | 09:24 | |
| *** harrymichal has joined #zuul | 09:31 | |
| openstackgerrit | Simon Westphahl proposed zuul/zuul master: Dispatch Gerrit events via Zookeeper https://review.opendev.org/c/zuul/zuul/+/783816 | 09:34 |
| openstackgerrit | Simon Westphahl proposed zuul/zuul master: Ensure single instance for active event gathering https://review.opendev.org/c/zuul/zuul/+/783817 | 09:34 |
| *** hashar has quit IRC | 09:52 | |
| *** jcapitao has quit IRC | 09:56 | |
| *** jcapitao has joined #zuul | 09:56 | |
| *** harrymichal has quit IRC | 09:57 | |
| *** harrymichal has joined #zuul | 09:57 | |
| openstackgerrit | Sorin Sbârnea proposed zuul/zuul master: WIP: Document tox environments https://review.opendev.org/c/zuul/zuul/+/766460 | 09:59 |
| *** harrymichal has quit IRC | 09:59 | |
| *** harrymichal has joined #zuul | 10:00 | |
| *** ykarel|lunch is now known as ykarel | 10:04 | |
| *** jcapitao has quit IRC | 10:36 | |
| *** jcapitao has joined #zuul | 10:36 | |
| *** jcapitao is now known as jcapitao_lunch | 10:39 | |
| *** jcapitao_lunch has quit IRC | 10:46 | |
| *** jcapitao_lunch has joined #zuul | 10:47 | |
| *** jcapitao_lunch has quit IRC | 10:51 | |
| *** jcapitao_lunch has joined #zuul | 10:51 | |
| *** mugsie__ is now known as mugsie | 11:01 | |
| *** jcapitao_lunch has quit IRC | 11:04 | |
| *** jangutter_ has joined #zuul | 11:36 | |
| *** jangutter has quit IRC | 11:39 | |
| *** jcapitao_lunch has joined #zuul | 11:46 | |
| *** sshnaidm|off is now known as sshnaidm | 11:57 | |
| icey | hey, is it possible to limit concurrency both globally (via semaphore) as well as per-change? I have a semaphore that can be copmletely consumed by a single ref and would like to spread the test reqources out a bit more to allow all jobs to continue slowly, rather than all blocking waiting on the first | 12:02 |
| *** jcapitao_lunch is now known as jcapitao | 12:02 | |
| *** wuchunyang has joined #zuul | 12:06 | |
| openstackgerrit | Guillaume Chauvel proposed zuul/zuul master: [DNM] run TestSchedulerSSL test with pending gear change https://review.opendev.org/c/zuul/zuul/+/780261 | 12:06 |
| icey | maybe something like supporting multiple semaphores on a job? | 12:07 |
| *** wuchunyang has quit IRC | 12:10 | |
| openstackgerrit | Simon Westphahl proposed zuul/zuul master: Make reporting asynchronous https://review.opendev.org/c/zuul/zuul/+/691253 | 12:22 |
| openstackgerrit | Daniel Blixt proposed zuul/zuul-jobs master: WIP: Make build-sshkey handling windows compatible https://review.opendev.org/c/zuul/zuul-jobs/+/780662 | 12:42 |
| openstackgerrit | Daniel Blixt proposed zuul/zuul-jobs master: WIP: Make build-sshkey handling windows compatible https://review.opendev.org/c/zuul/zuul-jobs/+/780662 | 12:45 |
| openstackgerrit | Daniel Blixt proposed zuul/zuul-jobs master: WIP: Make build-sshkey handling windows compatible https://review.opendev.org/c/zuul/zuul-jobs/+/780662 | 13:04 |
| *** harrymichal has quit IRC | 13:10 | |
| *** harrymichal has joined #zuul | 13:10 | |
| openstackgerrit | Guillaume Chauvel proposed zuul/zuul master: [DNM] run TestSchedulerSSL test with pending gear change https://review.opendev.org/c/zuul/zuul/+/780261 | 13:17 |
| openstackgerrit | Daniel Blixt proposed zuul/zuul-jobs master: WIP: Make build-sshkey handling windows compatible https://review.opendev.org/c/zuul/zuul-jobs/+/780662 | 13:30 |
| openstackgerrit | Daniel Blixt proposed zuul/zuul-jobs master: WIP: Make build-sshkey handling windows compatible https://review.opendev.org/c/zuul/zuul-jobs/+/780662 | 13:34 |
| avass | icey: I can't come up with a good way to do that right now | 14:15 |
| icey | avass: thanks, I've got some gross ideas but nothing that sounds sane | 14:18 |
| avass | icey: I suppose you could limit the number of parallel jobs for a specific label and put different jobs on separate labels but that seems like an awkward way to do it | 14:19 |
| avass | the label would work like a semaphore in that case | 14:20 |
| openstackgerrit | Merged zuul/nodepool master: Bump dib requirement to 3.8.0 https://review.opendev.org/c/zuul/nodepool/+/784026 | 14:24 |
| *** jangutter has joined #zuul | 14:40 | |
| *** ykarel is now known as ykarel|away | 14:40 | |
| *** jangutter_ has quit IRC | 14:43 | |
| *** saneax has quit IRC | 14:51 | |
| clarkb | icey: avass a hacky method would be to sequence the jobs per change requiring each to finish in succession with job deps | 14:51 |
| clarkb | that would lower throughput if you are otherwise idle though | 14:52 |
| *** jfoufas1 has quit IRC | 14:53 | |
| fungi | there's also the serial pipeline manager, not sure if that helps or makes the stated problem worse | 14:54 |
| fungi | zuul-maint: i know we don't usually end up doing anything at the open infrastructure project teams gathering event, but just in case we want to this time for some reason, we can probably still book some slots even though it's technically past the deadline for communities to sign up | 14:56 |
| fungi | let me know if there's interest and i can help coordinate. we can of course also do something similar in an unofficial capacity if desired | 14:57 |
| icey | clarkb: I think that's going to be the direction I look in :-/ | 14:58 |
| *** harrymichal has quit IRC | 15:00 | |
| *** harrymichal has joined #zuul | 15:00 | |
| *** ajitha has quit IRC | 15:03 | |
| openstackgerrit | Guillaume Chauvel proposed zuul/zuul master: [DNM] run TestSchedulerSSL test with pending gear change https://review.opendev.org/c/zuul/zuul/+/780261 | 15:13 |
| avass | clarkb: oh like using job.dependencies without there actually being a dependency? | 15:23 |
| *** johanssone has quit IRC | 15:26 | |
| clarkb | avass: ya | 15:28 |
| clarkb | just artificially sequence them | 15:28 |
| *** johanssone has joined #zuul | 15:29 | |
| *** ykarel|away has quit IRC | 15:37 | |
| *** hashar has joined #zuul | 15:41 | |
| clarkb | fungi: I've started looking at a test for the update needed behavior | 15:43 |
| clarkb | I'm running tox now for the first time against a sort of base layer setup on the test. Once that is good it shouldn't be too difficult to update the rest of the test to confirm failure in the scenario we've got | 15:43 |
| openstackgerrit | Felix Edel proposed zuul/zuul master: Make buildset mandatory on build https://review.opendev.org/c/zuul/zuul/+/770900 | 15:45 |
| openstackgerrit | Felix Edel proposed zuul/zuul master: Switch to ZooKeeper backed build result events https://review.opendev.org/c/zuul/zuul/+/782939 | 15:45 |
| openstackgerrit | Felix Edel proposed zuul/zuul master: DNM Deactivate statsd collection for online executors and running builds https://review.opendev.org/c/zuul/zuul/+/782940 | 15:45 |
| openstackgerrit | Felix Edel proposed zuul/zuul master: Execute builds via ZooKeeper https://review.opendev.org/c/zuul/zuul/+/770902 | 15:45 |
| fungi | clarkb: oh, thanks, my morning got hijacked by a variety of other problems | 15:45 |
| felixedel | corvus: Here is the latest version of the "ZooKeeper builds API" stack (https://review.opendev.org/c/zuul/zuul/+/770902/18) which also includes the "build result events via ZooKeeper" change (https://review.opendev.org/c/zuul/zuul/+/782939/3) | 15:49 |
| *** spotz has joined #zuul | 15:50 | |
| *** jangutter_ has joined #zuul | 15:58 | |
| clarkb | corvus: to run zk locally with the ca I first run zuul/tools/zk-ca.sh $PATH zuul-test-zookeeper then start the zuul-test-zookeeper container out of tools/docker-compose.yaml ? | 16:01 |
| *** jangutter has quit IRC | 16:01 | |
| guillaumec | clarkb, ./tools/test-setup-docker.sh | 16:02 |
| clarkb | guillaumec: cool thanks that helps confirm what I'm doing (I don't need a sql server for the usbset of tests I'm running os just getting the zk up is good for me and I basically did what that does) | 16:05 |
| guillaumec | clarkb, i can't count the number of time I forgot to start zk/mysql for tests so I made a simple script on top of that to run tox :) http://paste.openstack.org/show/804082/ | 16:08 |
| *** hamalq has joined #zuul | 16:18 | |
| *** hamalq_ has joined #zuul | 16:19 | |
| *** hamalq has quit IRC | 16:22 | |
| openstackgerrit | Sorin Sbârnea proposed zuul/zuul master: WIP: Document tox environments https://review.opendev.org/c/zuul/zuul/+/766460 | 16:26 |
| *** jcapitao has quit IRC | 16:40 | |
| *** hamalq_ has quit IRC | 16:41 | |
| *** hamalq has joined #zuul | 16:41 | |
| clarkb | fungi: now I am confused beacuse my test succeeds rather than fails | 17:03 |
| fungi | maybe there's an extra ingredient we're missing | 17:06 |
| clarkb | ya I am beginning to suspect the fake repo state I am feeding in doesn't quite match production | 17:08 |
| clarkb | I *think* that I shouldn't send the refs/changes/01/1/1 on the final event because in taht case we're simulating just running off of master | 17:09 |
| *** jangutter has joined #zuul | 17:09 | |
| clarkb | yup now I'm reproducing | 17:10 |
| clarkb | separately I ran into the re2 wheel is stale problem again, do you knwo if we can specify a dep specific rule to not use a cached wheel? | 17:12 |
| clarkb | if so that would be nice to add to zuul's dep for re2 | 17:12 |
| *** jangutter_ has quit IRC | 17:13 | |
| *** harrymichal has quit IRC | 17:16 | |
| corvus | o/ i'm getting started on looking into the memory leak now | 17:19 |
| fungi | clarkb: as in pip doesn't rebuild the wheel but your underlying libs have changed? | 17:22 |
| fungi | you can pass options to pip to not use its cache, but i'm not aware of any ability to do that on a per-package case unless pip is invoked separately for each package | 17:22 |
| *** harrymichal has joined #zuul | 17:23 | |
| openstackgerrit | Clark Boylan proposed zuul/zuul master: Update branches after fast forward merges https://review.opendev.org/c/zuul/zuul/+/784142 | 17:26 |
| clarkb | fungi: yes exactly, the so is different and the wheel that is cached no longer works | 17:27 |
| clarkb | fungi: ^ that tests the issue and fixes it. Running that test without the fix fails and passes with it | 17:27 |
| fungi | clarkb: i don't think the pipists have worked out a solution to that, but might be worth asking on the distutils-sig ml | 17:27 |
| clarkb | fungi: since pip caches with hashed dir paths I just rm the entire wheel cache | 17:28 |
| clarkb | which is a bit heavy weight but maybe decent hygiene | 17:28 |
| fungi | clarkb: i upgrade my primary python build fairly often, so have scripted a wipe of the wheel cache any time i do that | 17:28 |
| mordred | one would imagine just adding an soname to the wheel metadata would be helpful - but I'm sure there's a good reason that's not practical | 17:28 |
| avass | corvus: there's a memory leak? | 17:45 |
| corvus | avass: yep, current master; 4.1.0 should be fine. http://cacti.openstack.org/cacti/graph.php?action=view&local_graph_id=64792&rra_id=all | 17:45 |
| fungi | looked like once we ran out of system memory for caches, and started to push into swap even a little, zk disconnects cropped up | 17:47 |
| *** nils has quit IRC | 17:47 | |
| fungi | which was the initial symptom we observed | 17:47 |
| fungi | a quick scheduler restart to free up memory, and zk connection was back to steady for us again | 17:48 |
| avass | good thing I've been waiting to upgrade volvos zuul just in case of issues with >4.1 | 17:48 |
| corvus | yeah, if you want to help find issues, run master; if you want to be a little more conservative, run a point release since we usually only make those when we've seen production use on opendev just in case there are issues like this | 17:49 |
| *** vishalmanchanda has quit IRC | 17:51 | |
| fungi | it's a relatively slow leak in our deployment, takes at least 24 hours under fairly heavy load to consume the 30gb of ram we've allocated | 17:51 |
| corvus | yeah, there's a good chance most production deployments wouldn't notice it | 17:52 |
| fungi | which ends up being ~20gb ram and ~8gb cache and ~2gb buffers and then as we get a few 100mb into swap things begin to go bad | 17:53 |
| avass | I usually make sure we follow master during more stable periods but hold off on upgrading when there are bigger changes like this | 17:55 |
| corvus | good call | 17:55 |
| *** avass has quit IRC | 17:56 | |
| *** yourname has joined #zuul | 17:57 | |
| *** yourname is now known as avass | 17:58 | |
| avass | anyone knows if it's possible to gracefully shutdown irssi and save the scrollback somehow? :) | 18:00 |
| *** avass has quit IRC | 18:00 | |
| *** yourname has joined #zuul | 18:01 | |
| *** yourname is now known as avass | 18:02 | |
| clarkb | avass: I think if you set up logging it can reload it? | 18:02 |
| avass | clarkb: oh autolog? I'll look at that | 18:04 |
| clarkb | I've been on weechat for a long time and don't remember how to do irssi | 18:06 |
| *** avass has quit IRC | 18:07 | |
| *** yourname has joined #zuul | 18:10 | |
| *** yourname is now known as avass | 18:10 | |
| *** avass has quit IRC | 18:17 | |
| *** yourname has joined #zuul | 18:18 | |
| *** yourname is now known as avass | 18:18 | |
| *** avass has quit IRC | 18:19 | |
| *** yourname has joined #zuul | 18:19 | |
| *** yourname has quit IRC | 18:21 | |
| *** avass has joined #zuul | 18:21 | |
| corvus | 1 hour into most common object count with no results yet | 18:27 |
| clarkb | I think it may have paused things too? | 18:28 |
| clarkb | at least my change above hasn't started jobs last I checked | 18:28 |
| corvus | it's definitely slowed, but i don't think completely stopped | 18:29 |
| corvus | check has items enqueued 17m ago | 18:30 |
| corvus | (but obv that's a 17m mini-pause) | 18:30 |
| corvus | i've hashtagged all of the changes between the last 2 restarts with "leak"; those are our suspects | 18:31 |
| corvus | it returned | 18:32 |
| corvus | 2021-03-31 18:30:16,464 DEBUG zuul.stack_dump: mappingproxy 16835504 +16835504 | 18:32 |
| corvus | that's it | 18:32 |
| clarkb | https://review.opendev.org/q/hashtag:%22leak%22+(status:open%20OR%20status:merged) if anyone wants a link to those | 18:32 |
| corvus | that is not what i expected | 18:33 |
| corvus | i would typically read that as objgraph telling us that since startup, the only thing that the scheduler has done is create 16,835,504 mappingproxy objects, and no objects of any other type. | 18:33 |
| corvus | normally, i would expect to run that again and see the delta, but i'm not sure i'd expect any useful info; what do you think clarkb? | 18:35 |
| clarkb | ya I think the only reason to run it again would be to turn off yappi? | 18:36 |
| corvus | good point; i'll go ahead and do that | 18:36 |
| corvus | i think we may also be in the middle of a reconfiguration | 18:38 |
| corvus | which normally pauses queues; with that process being slow due to objgraph, effect is exacerbated | 18:38 |
| corvus | returned faster this time: | 18:42 |
| corvus | 2021-03-31 18:38:35,321 DEBUG zuul.stack_dump: dict 8690210 +12910 | 18:42 |
| corvus | still only one type | 18:42 |
| clarkb | corvus: is it interleaved or otherwise hidden in the logs for some reason? | 18:42 |
| clarkb | that is really odd though | 18:43 |
| corvus | let me check i'm not messing up the grep | 18:43 |
| corvus | oh yep that's it; it's a multiline output with only one prefixed line | 18:43 |
| corvus | i wonder why the multiline logging fix didn't handle that | 18:44 |
| corvus | initial: http://paste.openstack.org/show/804091/ | 18:46 |
| corvus | second: http://paste.openstack.org/show/804092/ | 18:46 |
| corvus | 208 layouts currently | 18:46 |
| corvus | i need to run; biab | 18:47 |
| clarkb | that seems like a very high nodeset and job count | 18:50 |
| clarkb | the executor refactor does involve jobs and nodesets | 18:58 |
| *** y2kenny has joined #zuul | 19:00 | |
| *** hashar has quit IRC | 19:08 | |
| clarkb | I've looked over that one a bit and don't think it substantially changed anything frombefore. It was largely a refactor | 19:34 |
| clarkb | the semaphores in zk chnage does stand out though since it updates how configs/layouts/semaphores are managed | 19:34 |
| clarkb | in particular every layout seems to get a new semaphore object which hangs on to the layout? could it be we've created a loop there peventing things from cleaning up? | 19:35 |
| clarkb | in the past we carried the existing semaphore object forward and only ever had the one per config level semaphore | 19:35 |
| fungi | so any layout with a semaphore is effectively still referenced and the gc can't clean it up? | 19:35 |
| clarkb | maybe. I'm still tryin to understand the change better, and my desktop had a crash during updates :( | 19:36 |
| clarkb | I'm going to complete updates and reboot and get to a happy spot then pull that change back up again | 19:36 |
| fungi | proof that updating software is always a bad idea | 19:36 |
| clarkb | the thing that stood out to me initially in that is we pass tenant.layout to the semaphore object and the old code that passes semaphores forward across layouts was removed (its a big old red blob in gerrit) | 19:38 |
| clarkb | https://review.opendev.org/c/zuul/zuul/+/772513/9/zuul/scheduler.py is where we would carry things forward before. https://review.opendev.org/c/zuul/zuul/+/772513/9/zuul/configloader.py is where we maybe put things into a loop | 19:49 |
| clarkb | though I'm noticing this is at a tenant level so we should only have one per tenant? | 19:50 |
| fungi | one what? | 19:50 |
| fungi | layout? | 19:50 |
| clarkb | one semaphore handler per tenant | 19:51 |
| clarkb | but I don't know how frequently zuul recreates tenant objects | 19:51 |
| clarkb | tenant refers to layout and semaphore hander, semaphore hander refers to tenant.layout | 19:51 |
| clarkb | is that sufficient to confuse python gc? | 19:52 |
| fungi | does that include speculative layouts? | 19:53 |
| clarkb | I think so? the pastes above show ~208 total layouts | 19:55 |
| clarkb | but maybe not since it see we go Config -> Tenants -> TenantProjectConfigs | 19:56 |
| clarkb | and the TenantProjectConfigs are the speculative bits I think | 19:57 |
| corvus | clarkb: yeah, i had observed the same thing and it was at the top of my list of suspects. | 19:57 |
| corvus | theoretically, the gc should be able to clear that sort of thing up... but... | 19:58 |
| corvus | i'm back from lunch and will start trying to see if those layouts are orphaned or really in use | 19:58 |
| corvus | zuul's load has leveled off (we're now running at < capacity) and the memory use is not growing | 20:00 |
| corvus | so we may have some headroom to poke at this before running out of ram; otoh, if we have to restart, we may not see significant leaking again until traffic picks up (could be as late as tuesday?) | 20:00 |
| corvus | i'm going to try really hard not to break it :) | 20:01 |
| clarkb | k | 20:01 |
| avass | updating my config project bumped my scheduler memory usage form 109mb to 126mb (four commits changing job config), another change bumped it to 128mb, and a third bumped it to 130mb. that 109mb had been stable since I started logging at 19:00 | 20:02 |
| avass | without any traffic to that zuul instance before I updated the config project that is :) | 20:04 |
| fungi | yeah, i doubt it's leaking at rest, almost certainly related to activity | 20:04 |
| fungi | so i wouldn't be surprised if there was no increase in memory while the scheduler was idle | 20:05 |
| avass | oh and there were no jobs running for that, it was just pushed directly to master without any project config at all | 20:08 |
| corvus | i've collected the known layouts reachable from the abide; there are 26. objgraph says there are now 262 in memory. | 20:09 |
| corvus | starting to look like a layout leak | 20:10 |
| fungi | so 10x more than there should be | 20:10 |
| corvus | the other ones clarkb called out: nodesets and jobs, right? those are likely hanging off of layouts | 20:11 |
| corvus | so i think we continue poking at layouts | 20:11 |
| fungi | the graph does look reminiscent of the last layout leak we had too, where the growth rate isn't steady but has some occasional stiff slopes | 20:11 |
| fungi | if you get a stack of changes to job configuration then you can eat a bunch of memory fast, but other times it's just one here or there | 20:13 |
| clarkb | corvus: ya nodestes and jobs seemed high and hanging off of layouts makes sense | 20:13 |
| corvus | i'm starting to do some more intensive objgraph queries; this could end up causing zk disconnects | 20:17 |
| corvus | i'm doing a backref search on one of the leaked layouts with a depth of 10; i seem to remember last time that was about enough to get the info we needed without running for hours | 20:23 |
| corvus | (objgraph default is 20) | 20:23 |
| clarkb | if it is the loop I wrote down then ~2 should be enough to see it? | 20:24 |
| clarkb | maybe 3? | 20:25 |
| corvus | yeah, was thinking maybe 5 or so might be a better value; sort of a tradeoff with not wanting to run it twice. | 20:26 |
| corvus | clarkb: if we're not looking at a GC bug, then it's not actually the loop that's the problem, we'd actually expect the whole loop to be hanging off of something else unexpected, so that could end up needing a couple more steps to identify the cause | 20:27 |
| corvus | and apparently i just said we expect the unexpected | 20:27 |
| clarkb | software is all about resetting expectations | 20:28 |
| corvus | s/expectations// | 20:28 |
| corvus | it's done and there are a lot of zk errors, so i think we just lost the zk connection and will be restarting all the jobs | 20:30 |
| corvus | hopefully got good data though | 20:30 |
| fungi | i have great expectations | 20:31 |
| clarkb | it should recover from that on its own as long as memory didn't spike too high and stay there | 20:31 |
| avass | I think disconnecting from zk could lead to memory leaks as well, at least that's what happened to us when we needed to increase our zk timeout | 20:32 |
| clarkb | avass: in this case based on logs yesterday I'm fairly sure that wasn't the cause but a side effect, though it may have caused things to get worse as it happened more | 20:33 |
| clarkb | the memory use started climbing well before the disconnects | 20:33 |
| fungi | i could see that creatinga feedback loop, yeah | 20:34 |
| avass | clarkb: yeah I'm just saying that the memory usage could increase from dropping connection to zk now | 20:34 |
| fungi | basically you leak something based on what builds are running, zk disconnects cause way more builds to end up running total, leaking more and faster | 20:34 |
| fungi | chain reaction | 20:34 |
| corvus | the backref chain was not helpful; it had no other objects. | 20:35 |
| tobiash | avass: the memleak on zk session loss should have been been fixed meanwhile: https://review.opendev.org/c/zuul/zuul/+/751170 | 20:35 |
| corvus | so either i did the query wrong, or the leaked layout has no references and we're looking at a gc issue | 20:35 |
| tobiash | corvus: do the new changes serialize exception tracebacks? | 20:36 |
| corvus | tobiash: yes, they should be strings | 20:36 |
| corvus | (i remember thinking about that in review :) | 20:37 |
| tobiash | our last leak was caused by the traceback creation which also was very hard to see in the object graph | 20:37 |
| corvus | possible we missed a case | 20:37 |
| tobiash | fix was https://review.opendev.org/c/zuul/zuul/+/751171/1 back then | 20:37 |
| avass | tobiash: oh yeah I think we might have been on an older version back then | 20:38 |
| corvus | running it again without the extra_ignore argument this time, in case that messed it up | 20:40 |
| corvus | i wonder if we could patch objgraph and give it a "nice" argument | 20:41 |
| tobiash | corvus: I wonder if that leaks: https://opendev.org/zuul/zuul/src/branch/master/zuul/scheduler.py#L1292 | 20:45 |
| tobiash | the traceback fix back then needed to explicitly clear the frames on the traceback: https://review.opendev.org/c/zuul/zuul/+/751171/1/zuul/scheduler.py | 20:45 |
| tobiash | I think we should try the same there | 20:45 |
| tobiash | and there: https://opendev.org/zuul/zuul/src/branch/master/zuul/scheduler.py#L1329 | 20:45 |
| clarkb | fungi: unrelated to memory issues https://review.opendev.org/c/zuul/zuul/+/784142 passed testing | 20:46 |
| corvus | tobiash: but the traceback obj should be deleted in this case | 20:47 |
| corvus | it wasn't then -- we kept tb around | 20:47 |
| tobiash | we've read that there are some problems around traceback that produce unintended memleaks | 20:47 |
| corvus | (though even then, tb should have eventually been deleted, so maybe whatever that problem was; it's still relevent) | 20:47 |
| corvus | hrm | 20:47 |
| corvus | tobiash: were you able to see this with objgraph? | 20:48 |
| tobiash | the problem is that the traceback references the frames which are not necessary for formatting and those frame objects seem to be some kind of special | 20:48 |
| corvus | maybe if i run find_backref_chain without the is_proper_module check? | 20:49 |
| tobiash | corvus: not really, or at least it was very hard | 20:49 |
| tobiash | if the objgraph is deep enough you might see 'frame' objects | 20:49 |
| tobiash | but we've seen them only within a graph that was too large to be rendered in a useful way | 20:50 |
| corvus | right now, i have zero references to the leaked layout | 20:50 |
| corvus | i re-ran without the extra_ignore, and got a single reference from my local variables | 20:51 |
| corvus | so that's confirming that there are no refs to this layout except from things that objgraph thinks are GC roots | 20:51 |
| clarkb | the most recent python3.8 release was February 19, I suspect we've been running on that for a while now which makes me think GC bug is less likely | 20:52 |
| clarkb | iirc we updated the base images to pick that up due to the c float thing | 20:53 |
| openstackgerrit | Tobias Henkel proposed zuul/zuul master: Fix possible memory leak when dealing with exceptions https://review.opendev.org/c/zuul/zuul/+/784165 | 20:53 |
| tobiash | corvus: we could just try something like this and see if that fixes the leak ^ | 20:54 |
| corvus | tobiash: i'm not sure that we're going to see a noticable leak again until tuesday if we restart; i really want to try to understand the leak based on what's happening now while we have the chance | 20:55 |
| corvus | if we just guess and we're wrong, we'll spend a lot more time on it. i agree that's something to try if we can't come up with anything else. | 20:55 |
| corvus | but when we get down to throwing stuff at the wall, i'd also probably remove the semaphore layout loop too :) | 20:56 |
| tobiash | can you see if objdump finds objects of type 'frame'? | 20:56 |
| tobiash | oh, I guess I missed the semaphore layout loop in the scrollback | 20:57 |
| clarkb | tobiash: its not a proper loop and should be able to be cleaned | 20:58 |
| corvus | it's just a loop -- it shouldn't be a problem. so like this, it's something to try when we've excluded everything that should be a problem :) (the sherlock holmes theory) | 20:58 |
| corvus | even proper loops should be able to be cleaned | 20:58 |
| clarkb | but it stood out among the change list of potential problems | 20:58 |
| clarkb | corvus: it tackles them in multiple passes I think? so old tenant would be cleaned up but then tenant.layout would hang around until semaphore handler was also removed | 20:59 |
| corvus | tobiash: re exceptions -- we've seen the layout leak grow over the past few hours, but i don't think we've been submitting many management events during that time, so i don't think there would be many chances for that exception handler to run? | 21:00 |
| corvus | tobiash: objgraph found 1948 frames | 21:00 |
| corvus | they may be paramiko frames | 21:00 |
| corvus | oh, no, these are the right kind of frames | 21:02 |
| corvus | that's a frame from a paramiko stacktrace | 21:02 |
| corvus | gimme a minute; we don't have less installed on our images :/ | 21:02 |
| clarkb | I think more may be on them | 21:03 |
| clarkb | (not as useful but sometimes good enough) | 21:03 |
| corvus | yes, i keep scrolling past line 623 | 21:03 |
| clarkb | fungi can probably tell me why less is more useful than more | 21:03 |
| corvus | cause you can scroll up? | 21:04 |
| fungi | that | 21:04 |
| mordred | yup | 21:04 |
| corvus | okay, so the first frame object i found is in an exception handler in _addressfamily_host_lookup in '/usr/local/lib/python3.8/site-packages/paramiko/config.py' | 21:04 |
| corvus | so something is keeping exception frames around | 21:05 |
| fungi | i usually prefer view to less, but it can eat a bunch of memory for very large files | 21:05 |
| avass | clarkb: because less is more ;) | 21:05 |
| fungi | avass even knows the tagline | 21:05 |
| clarkb | ya I use a lot of view too | 21:06 |
| corvus | we also don't have view | 21:06 |
| corvus | objgraph does not think that a frame is a GC root, so it should show up in the backref search | 21:06 |
| clarkb | corvus: can you backref against the frame and see what refers to it? | 21:07 |
| corvus | yeah, will do in a min; | 21:07 |
| corvus | a lot of frames are kazoo.recipe.watchers; we may want to look at that | 21:08 |
| corvus | i'm poking at frames; i think we can reconstruct a backtrace from a frame by looking at the f_back attr, which is another frame. so maybe every frame with a null f_back is the top of a stacktrace, then work down from there. | 21:11 |
| corvus | i think if we did that, we'd have a full stacktrace for every frame currently; may be able to identify suspicious code locations | 21:12 |
| corvus | like if one of those frames had tobiash's fixed lines in it, we might know his change would be effective | 21:13 |
| clarkb | neat | 21:13 |
| mordred | ++ | 21:14 |
| corvus | i verified that objgraph doesn't think frame.f_locals is a GC root, so if a frame links to a layout via locals, it should still show up in objgraphs backrefs -- assuming that objgraph found the frame or the locals object. maybe one or the other of those are special and don't show up in the backref gather phase | 21:15 |
| corvus | that comes from gc.get_referrers; i wonder if frames or frame.f_locals are somehow invisible to that | 21:19 |
| corvus | hrm, a quick test shows gc.get_referrers is capable of returning frame objects | 21:22 |
| corvus | i'm going to try to get those stacktraces now | 21:23 |
| corvus | that half-worked. i got some stacktraces out of it, but a bunch of frames which didn't have a top. | 21:40 |
| corvus | i wonder what the remainder look like; i'll keep poking | 21:40 |
| corvus | tobiash: one of my reassembled stack traces is a single stacktrace with a single frame: <frame at 0x7fdbd4039230, file '/usr/local/lib/python3.8/site-packages/zuul/scheduler.py', line 1234, code process_global_management_queue> | 21:55 |
| corvus | that line number is wrong, but i'm pretty sure it's pointing at one of your fixes | 21:56 |
| clarkb | process_global_management_queue is the wrong functions too (though if it uses the line numbers to help determine that could be wrong too?) | 21:57 |
| corvus | clarkb: it calls _forward_management_event which is one of tobiash's fixes | 21:57 |
| clarkb | oh though that function calls ya that | 21:57 |
| corvus | i'm unsure of the significance of this -- it may suggest the fix is necessary, but i'm having trouble convincing myself that it's responsible for all the leaks since it's only a single frame | 21:57 |
| corvus | meanwhile, there are hundreds of stacktraces with kazoo tracebacks. i don't know why we have frames for them since they don't seem to be in excepton handlers that call traceback.* functions | 21:58 |
| corvus | maybe those are just bad luck? maybe i called objgraph.by_type soon enough after the zk disconnect that the gc just hadn't gc'd all the execptions that caused? | 22:01 |
| corvus | maybe if i cleared things out and re-did it, there wouldn't be so many? | 22:01 |
| corvus | (but if that's the case, then that would also explain why the global management frame was in there -- it would be innocent after all) | 22:02 |
| clarkb | that is an interesting idea | 22:02 |
| *** fsvsbs has joined #zuul | 22:34 | |
| fsvsbs | https://www.irccloud.com/pastebin/79aPsq33 | 22:36 |
| clarkb | tristanC: uses the operator I think | 22:37 |
| clarkb | and may be able to help | 22:37 |
| tristanC | fsvsbs: what is the actual exception? | 22:39 |
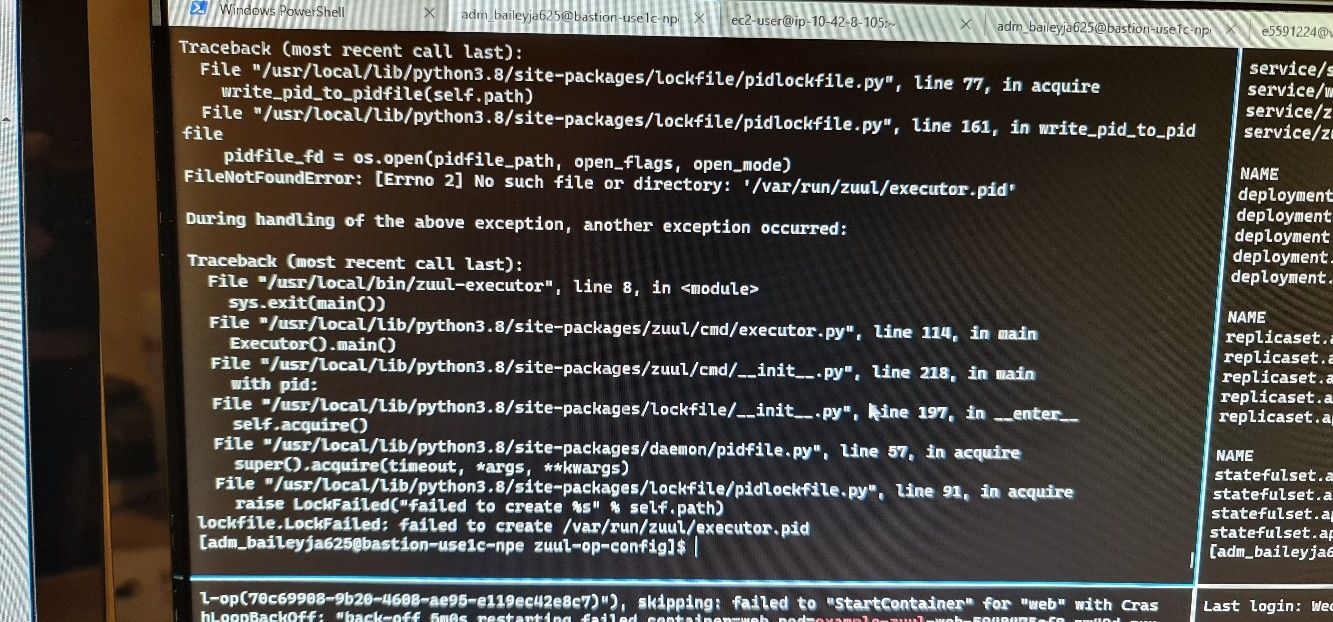
| fsvsbs | Hi tristanC have you come across failed to create /var/run/zuul/[container].Pid | 22:40 |
| fsvsbs | Lockfile failed | 22:40 |
| openstackgerrit | Tristan Cacqueray proposed zuul/zuul-operator master: DNM: Testing zuul-operator https://review.opendev.org/c/zuul/zuul-operator/+/784180 | 22:40 |
| fsvsbs | https://usercontent.irccloud-cdn.com/file/4Yx6rci6/irccloudcapture3460549349975442300.jpg | 22:41 |
| corvus | tristanC, fsvsbs: i think the operator overrides the container command, but we should no longer do that. | 22:42 |
| corvus | the container command is now "zuul-* -f" which is correct for a k8s, but the operator runs "zuul-* -d" | 22:43 |
| *** harrymichal has quit IRC | 22:47 | |
| openstackgerrit | Tristan Cacqueray proposed zuul/zuul-operator master: Remove command args override https://review.opendev.org/c/zuul/zuul-operator/+/784181 | 22:49 |
| corvus | gc.get_referrers() on one of the leaked layouts returns a dictionary that looks a lot like a __dict__ of a zuul model object; i'm trying to suss out which | 23:01 |
| corvus | (that's the only one of the 4 referrers i can't identify) | 23:02 |
| corvus | it's a QueueItem | 23:03 |
| corvus | so we have the gc module telling us that a QueueItem's __dict__ holds a reference to our leaked layout (but for some reason, this got filtered out of objgraph's chain) | 23:04 |
| corvus | gc has given me the next link -- it is in fact a queueitem | 23:07 |
| corvus | i'm basically doing the objgraph algorithm by hand; i'm not sure why it failed | 23:07 |
| *** tosky has quit IRC | 23:30 | |
| corvus | oh... it's show_backrefs i should be looking at, not find_backref_chain | 23:32 |
| corvus | or i do need to call find_backref_chain but with a higher max_depth until it returns something > 1 | 23:42 |
| corvus | anyway, making progress now; just slowly | 23:42 |
Generated by irclog2html.py 2.17.2 by Marius Gedminas - find it at https://mg.pov.lt/irclog2html/!
{kind=link}