| *** mazzy509881 is now known as mazzy50988 | 00:10 | |
| *** mazzy509889 is now known as mazzy50988 | 00:34 | |
| corvus | last zuul bugfix change merged; waiting for promote | 01:39 |
|---|---|---|
| corvus | once it does promote, i'll pull the images, then i'll restart zuul01 with the new image, wait for it to settle, then do the same for zuul02 | 01:40 |
| corvus | promote is done, pulling images | 01:41 |
| corvus | stopping zuul01 | 01:43 |
| corvus | we have some work to do on the shutdown sequence, but it's stopped. | 01:45 |
| corvus | starting 01 again | 01:45 |
| corvus | https://zuul.opendev.org/components is now interesting; you can see the new version # on zuul01 | 01:45 |
| corvus | as zuul01 is coming online expect occasional status page errors; that's harmless | 01:46 |
| fungi | what needs to be adjusted for shutdown now? i guess to do the rolling scheduler restarts? | 01:48 |
| corvus | it looks like we don't wait to finish the run handler before we disconnect from zk | 01:49 |
| fungi | ahh, that could be messy i guess | 01:49 |
| corvus | (sorry, to be clear, i mean the scheduler program itself, not opendev ops) | 01:49 |
| fungi | makes sense, thanks | 01:50 |
| corvus | i just realized one of the changes was not backwards compat, so i'm going to go ahead and shut down zuul02 | 01:51 |
| corvus | otherwise it's going to throw more and more errors | 01:51 |
| fungi | too bad | 01:52 |
| fungi | we'll get a real rolling restart soon, i'm sure | 01:52 |
| corvus | i'm optimistic this can still be a rolling restart, just with a brief pause in processing | 01:52 |
| fungi | oh, right the state is still persisted | 01:53 |
| corvus | and zuul01 is already processing some tenants | 01:53 |
| corvus | they just happen to be the empty ones | 01:54 |
| corvus | okay that did not work | 01:58 |
| corvus | i'm going to shut it down, clear zk state, and restore queues from backup | 01:59 |
| fungi | thanks! | 01:59 |
| corvus | (i suspect that the non-backwards-compat change tanked it) | 01:59 |
| fungi | i can see how something like that could lead to an unrecoverable/corrupted state | 02:00 |
| corvus | starting up now | 02:03 |
| corvus | this'll be one of the longer startup times since the zk state is empty | 02:05 |
| corvus | re-enqueueing | 02:27 |
| corvus | re-enqueue done | 02:39 |
| corvus | i'm going to leave zuul01 off for now and start it up tomorrow morning | 02:40 |
| fungi | sounds good, thanks again! | 02:53 |
| *** ysandeep|out is now known as ysandeep | 04:37 | |
| *** ysandeep is now known as ysandeep|brb | 04:46 | |
| *** ykarel|away is now known as ykarel | 04:54 | |
| opendevreview | chandan kumar proposed opendev/system-config master: Enable mirroring of centos stream 9 contents https://review.opendev.org/c/opendev/system-config/+/817136 | 05:18 |
| *** ysandeep|brb is now known as ysandeep | 05:35 | |
| opendevreview | Ian Wienand proposed openstack/diskimage-builder master: containerfile: handle errors better https://review.opendev.org/c/openstack/diskimage-builder/+/817139 | 06:24 |
| ianw | there is still something wrong with the containerfile build. but hopefully this stops us getting into a broken state | 06:29 |
| *** ysandeep is now known as ysandeep|lunch | 07:40 | |
| *** sshnaidm is now known as sshnaidm|afk | 07:45 | |
| *** ykarel is now known as ykarel|lunch | 08:06 | |
| *** pojadhav- is now known as pojadhav | 08:49 | |
| *** ysandeep|lunch is now known as ysandeep | 09:06 | |
| *** gthiemon1e is now known as gthiemonge | 09:14 | |
| *** sshnaidm|afk is now known as sshnaidm | 09:40 | |
| *** ykarel|lunch is now known as ykarel | 09:54 | |
| *** dviroel|out is now known as dviroel | 11:07 | |
| *** ysandeep is now known as ysandeep|afk | 11:12 | |
| zbr | is anyone aware of storyboard issues? i wanted to unsubscribe me from its notifications and I discovered that it does not allow logins anymore. https://sbarnea.com/ss/Screen-Shot-2021-11-09-11-17-31.25.png --- that is what happens AFTER pressing the login with LP button. | 11:17 |
| *** pojadhav is now known as pojadhav|afk | 11:40 | |
| *** ysandeep|afk is now known as ysandeep | 12:05 | |
| *** pojadhav- is now known as pojadhav | 14:24 | |
| *** ysandeep is now known as ysandeep|dinner | 14:27 | |
| *** pojadhav- is now known as pojadhav | 14:39 | |
| opendevreview | Martin Kopec proposed opendev/irc-meetings master: Update QA meeting info https://review.opendev.org/c/opendev/irc-meetings/+/817224 | 14:48 |
| opendevreview | Martin Kopec proposed opendev/irc-meetings master: Update Interop meeting details https://review.opendev.org/c/opendev/irc-meetings/+/817225 | 14:49 |
| *** ykarel_ is now known as ykarel|away | 14:57 | |
| clarkb | zbr: I am unable to reproduce but can't dig in further than that for now as I need to do a school run and eat breakfast | 15:14 |
| corvus | i'm going to start zuul01 | 15:19 |
| corvus | status page blips may occur | 15:19 |
| *** ysandeep|dinner is now known as ysandeep | 15:22 | |
| fungi | zbr: i'm also able to log into storyboard just fine, and have additionally checked that your account is currently set to enabled | 15:25 |
| fungi | if you'd like me to unset your e-mail address from it, i'm happy to do that | 15:25 |
| corvus | zuul01 is running | 15:39 |
| opendevreview | Dmitriy Rabotyagov proposed openstack/project-config master: Create repo for ProxySQL Ansible role https://review.opendev.org/c/openstack/project-config/+/817271 | 16:06 |
| opendevreview | Dmitriy Rabotyagov proposed openstack/project-config master: And ansible-role-proxysql repo to zuul jobs https://review.opendev.org/c/openstack/project-config/+/817272 | 16:08 |
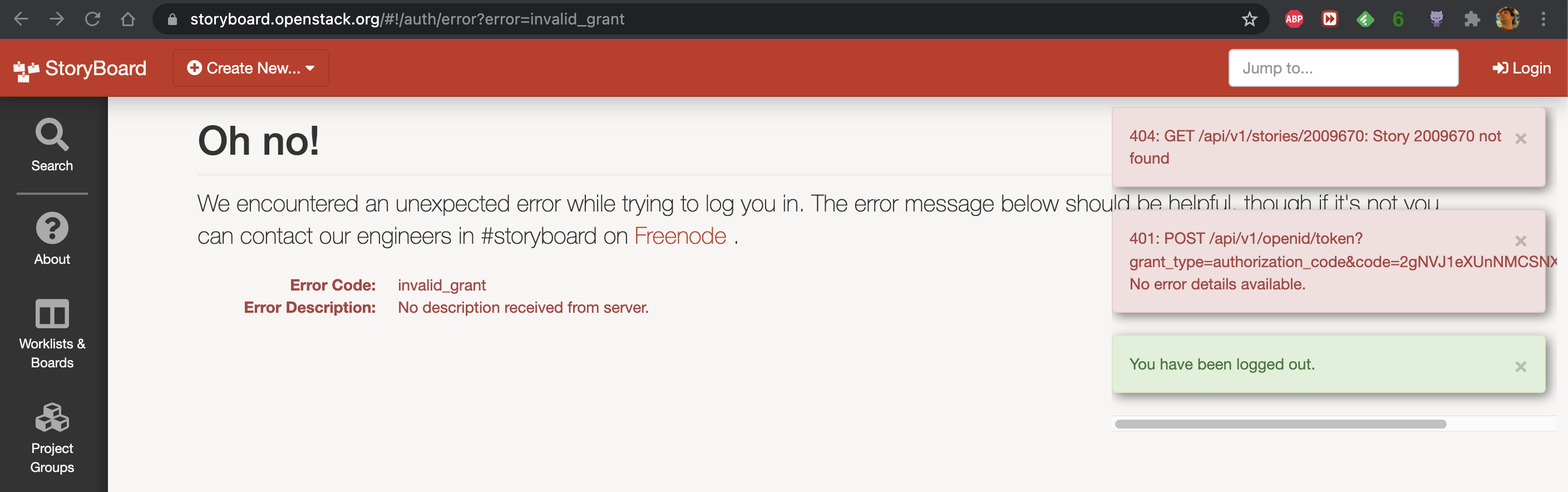
| zbr | clarkb: fungi no need to do anything. I was able to login succesfully and I think I found the bug in story board. Original notification was about a new weird story 1111111 being created this morning, with link to it https://storyboard.openstack.org/#!/story/2009670 -- when using this url and trying to login I got delogged automatically. When logging from homepage it did work. I guess that there is something fishy about this story, as it seems it was | 16:17 |
| zbr | removed. Still, this should never tigger user logout. | 16:17 |
| zbr | if i knew about this bug i would have not bothered to mention it here, but only few minutes ago i identified the root cause. | 16:17 |
| fungi | interesting, thanks for the heads up about the weird story, i'll see if i can tell where that came from | 16:17 |
| fungi | zbr: and i think the webclient problem you observed was reported as https://storyboard.openstack.org/#!/story/2008184 | 16:20 |
| fungi | seems to have to do with the openid redirect/return sending you back to an error page | 16:21 |
| *** ysandeep is now known as ysandeep|out | 16:21 | |
| clarkb | There are not changes in openstack's zuul tenant more than a few hours old implying we don't have any problems with things getting stuck again | 16:27 |
| clarkb | corvus: is it safe to restart zuul-web (I expect it is) in order to get the card sizing fix deployed | 16:56 |
| clarkb | I guess we'll probably do a restart for the pipeline path change and that would catch it too. That is probably good enough | 17:00 |
| corvus | clarkb: yes to both :) | 17:01 |
| *** marios is now known as marios|out | 17:02 | |
| clarkb | corvus: one thing I've noticed is that sometimes the status page doesn't give me an estimated completion time. I know this can be related to a lack of data in the database, but I would expect either scheduler to return the data from the database and not be an issue in a multi scheduler setup | 17:31 |
| clarkb | just calling that out in case there is potential for a bug here | 17:31 |
| clarkb | but for example change 817108,1 is running tripleo jobs I'm fairly certain we've run enough times previously to have runtime data in the db for | 17:32 |
| clarkb | but 3 of the 4 running jobs there don't give the hover over tooltip | 17:32 |
| clarkb | er 4 out of 5 | 17:32 |
| corvus | hrm i'll take a look | 17:33 |
| corvus | clarkb: i think i see the issue; more in #zuul | 17:54 |
| opendevreview | Clark Boylan proposed opendev/base-jobs master: Remove growroot logs dumping in base-test https://review.opendev.org/c/opendev/base-jobs/+/817289 | 18:08 |
| opendevreview | Clark Boylan proposed opendev/base-jobs master: Remove growroot log dumping from the base job https://review.opendev.org/c/opendev/base-jobs/+/817290 | 18:08 |
| clarkb | neither of ^ is particularly urgent but I noticed we were still dumping growroot logs when I was looking at a job today and thought we don't need that anymore and it can be distracting when skimming logs | 18:09 |
| opendevreview | Clint Byrum proposed zuul/zuul-jobs master: Remove google_sudoers in revoke-sudo https://review.opendev.org/c/zuul/zuul-jobs/+/817291 | 18:10 |
| fungi | zbr: that story you got notified about looks like it was a user testing out story creation and picking a couple of projects at random, them they set it to private once they realized they couldn't delete it (so i deleted it as an admin just now). thanks for bringing it to my attention | 18:27 |
| rosmaita | when someone has a few minutes ... zuul is giving me "Unknown configuration error" on this small change, and I can't figure out what I'm doing wrong: https://review.opendev.org/c/openstack/os-brick/+/817111 | 18:34 |
| clarkb | rosmaita: we think that was a bug in zuul that has since been corrected (as of like 02:00 UTC today or so) | 18:35 |
| rosmaita | \o/ | 18:35 |
| clarkb | rosmaita: if you try to recheck it should hopefully either run or give you back a proper error message | 18:35 |
| rosmaita | excellent, ty | 18:35 |
| clarkb | rosmaita: looks like it queued up jobs | 18:39 |
| rosmaita | great, thanks! | 18:40 |
| clarkb | if anyone wants details there was an issue trying to serialize too much data into individual zookeeper znode entries when processing zuul configs. When that happened zuul got a database error and that bubbled up to the user as an unknown error. corvus fixed that by sharding data serialized for configs | 18:40 |
| clarkb | fungi: re the @ username thing we can probably grep external ids for that somehow if we want to audit on our end | 18:50 |
| fungi | yeah, i just didn't have time to, and if it's important to the user they can check it | 18:51 |
| fungi | i'm finding so many stories which people have simply set to private rather than marking them invalid | 18:53 |
| clarkb | That might explain why it is common to only allow the private -> public transition and not the other way around? | 18:54 |
| fungi | though also i'm finding a bunch which people opened incorrectly as private when they're just normal bug reports | 18:55 |
| clarkb | corvus: really quickly before I've got to run the opendev meeting. elodilles notes that they had some failed openstack release jobs because zuul.tag wsn't set https://zuul.opendev.org/t/openstack/build/6708011371124d1e92a43a2702343ba2/log/zuul-info/inventory.yaml#47 is an example of that | 18:59 |
| clarkb | the job appears to have been triggered by ref/tags/foo | 18:59 |
| clarkb | I wouldn't have expected this to be a multi scheduler issue but maybe we aren't serializing that info properly? eg is tag missing in model.py somewhere? | 18:59 |
| johnsom | Has the zuul fix been deployed for the openstack instance? We are still seeing invalid configuration errors as of 10:44am (pacific) | 18:59 |
| clarkb | (I'd look myself but I really need to do the meeting now) | 19:00 |
| clarkb | johnsom: yes it was restarted yesterday evening pacific time with the expected fix for the "Unknown config error" thing | 19:00 |
| johnsom | https://review.opendev.org/c/openstack/designate/+/786506 | 19:00 |
| clarkb | johnsom: rosmaita just rechecekd a change in that situation and it successfully enqueued | 19:00 |
| johnsom | Yeah, I'm going to re-spin this patch anyway, but was surprised to see the same error still based on the scroll back. | 19:01 |
| clarkb | its possible there are multiple underlying issues and we only fixed one of them | 19:02 |
| clarkb | your error is different fwiw | 19:02 |
| johnsom | We saw this yesterday too. A parent patch had the config message, then child had this one. | 19:03 |
| clarkb | In this case the parent seems to have always been able to run jobs | 19:04 |
| corvus | johnsom: i don't see an issue with that change now? | 19:12 |
| jrosser_ | i'm seeing this: Nodeset ubuntu-bionic-2-node already defined <snip...> in "openstack/openstack-zuul-jobs/zuul.d/nodesets.yaml@master", line 2, column 3 | 19:13 |
| jrosser_ | on here https://review.opendev.org/c/openstack/ansible-role-python_venv_build/+/817219 | 19:13 |
| johnsom | corvus, yeah, 20 minutes later, I pushed a change to it, this time it started | 19:13 |
| artom | Same here, here's the review: https://review.opendev.org/c/openstack/whitebox-tempest-plugin/+/815557/7 | 19:45 |
| opendevreview | Ian Wienand proposed opendev/system-config master: gerrit: test reviewed flag add/delete/add cycle https://review.opendev.org/c/opendev/system-config/+/817301 | 19:51 |
| clarkb | https://opendev.org/openstack/openstack-zuul-jobs/src/branch/master/zuul.d/nodesets.yaml#L2-L12 is where we define ubuntu-bionic-2-node. I wonder if we're deserializing in such a way that we're overlapping the contents of that fiel somehow | 19:55 |
| opendevreview | Merged opendev/system-config master: Retry acme.sh cloning https://review.opendev.org/c/opendev/system-config/+/813880 | 20:22 |
| opendevreview | Merged opendev/system-config master: Switch IPv4 rejects from host-prohibit to admin https://review.opendev.org/c/opendev/system-config/+/810013 | 20:36 |
| corvus | clarkb: i'm not following the conversation very well; where do i start looking for the nodeset issue? | 20:45 |
| clarkb | corvus: https://review.opendev.org/c/openstack/ansible-role-python_venv_build/+/817219 there and alternatively https://review.opendev.org/c/openstack/whitebox-tempest-plugin/+/815557/7 | 20:45 |
| clarkb | the both have errors from zuul complaining that the ubuntu-bionic-2-node nodeset is already defined | 20:46 |
| clarkb | neither change seems to directly add a nodeset with a conflicting name, which is what the error would typically indicate | 20:46 |
| corvus | thanks | 20:47 |
| clarkb | looks like the second change was rechecked and successfully enqueued | 20:47 |
| clarkb | so this isn't a consistent failure. That is good for artom but less good for debugging it :) | 20:48 |
| sshnaidm | is there a problem with zuul.tag variable? I don't see it's passed anymore in "tag" pipeline jobs: https://92c4e0b4c5172d297c6a-24da3718548989a700aa54b9db0ff79c.ssl.cf1.rackcdn.com/612c3400c17c7a9d8b0d230383858331cb0cd653/tag/ansible-collections-openstack-release/7bbc0ba/zuul-info/inventory.yaml | 20:48 |
| clarkb | sshnaidm: yes, fix is in progress at https://review.opendev.org/c/zuul/zuul/+/817298 and will need a zuul restart to take effect | 20:48 |
| sshnaidm | clarkb, oh, thanks! | 20:48 |
| clarkb | this was discussed in #openstack-release | 20:49 |
| *** dviroel is now known as dviroel|out | 20:51 | |
| clarkb | corvus: one thing I notice is that that nodeset is the very first thing defined in that config file. Which means it would be the very first error seen if we had somehow duplicated the file in a config aggregation | 21:03 |
| corvus | clarkb: yeah, i was thinking along similar lines -- istr we might only report the first of many errors, so that may be what's going on. and this may be related to our storage issue yesterday (ie, we may have been storing the full set of errors) | 21:04 |
| clarkb | oh yup and once you add up the error for all the duplicate nodesets that can easily get large | 21:05 |
| corvus | yes, i confirmed we only include the first error in the change message | 21:06 |
| corvus | (we will include all the errors in inline comments, but that doesn't apply to this case) | 21:06 |
| corvus | still need a hypothesis for what's triggering the errors... :/ | 21:07 |
| clarkb | corvus: is it possible for us to use a cached value and a newly merged value? | 21:11 |
| corvus | honestly don't know | 21:12 |
| clarkb | we do log "Using files from cache for project" when using the cached files | 21:22 |
| clarkb | but when that happens we skip ahead in the loop and don't submit a cat job so it shouldn't be possible to append the two together | 21:23 |
| corvus | here's a clue: the errors for 817219 happened on zuul01, and that did not perform the most recent reconfiguration of openstack; zuul02 did. zuul01 updated its layout because it detected it was out of date. so there may be a difference between a layout generated via a reconfiguration event, versus noticing the layout is out of date. but it's also possible this is happening merely because it's not the same host as where the reconfiguration | 21:23 |
| corvus | happened. i'll see if the other change can narrow it down further. | 21:23 |
| corvus | 815557 is the same situation but reversed: it happened on zuul02, but the most recent tenant reconfig happened on zuul01, so zuul02 was updated via the up-to-date check. that doesn't narrow it down much other than to say that it's not host-specific, and it does strongly point toward a cross-host issue | 21:27 |
| corvus | i wonder if the configuration error keys can somehow be different in either of those two circumstances | 21:28 |
| corvus | but hrm, this isn't an existing error, so that shouldn't matter. | 21:29 |
| clarkb | looking at the code I can see how we maybe read from the cache when it isn't fully populated (because we clear the entire cache before updating it with the write lock but when we read we don't seem to use a read lock) | 21:29 |
| clarkb | but I cannot see anything that looks like it would allow us to double up a file so far | 21:30 |
| clarkb | would zuul.d/nodesets.yaml be considered an extra_config_files? | 21:34 |
| corvus | (i just realized we also don't log all of the errors in the debug log, but they are all available in the web, so i checked all the tenants and none of them have an error related to ubuntu-bionic-2-node so i think our assumptions hold) | 21:35 |
| corvus | clarkb: no those should only be like zuul-tests.d/ in zuul-jobs | 21:35 |
| clarkb | got it | 21:35 |
| clarkb | also correction above we do use a read lock that corresponds to the write lock so that should be fine | 21:36 |
| corvus | the configuration error keys in the layout loading errors do have different hashes on the two different schedulers. that makes me think that we could incorrectly filter out config errors when constructing layouts. if we knew that the ubuntu-bionic-2-node was an existing config error, then i would say that's the culprit and what needs to be fixed. but i'm troubled by the fact that we don't know where that error is actually coming from. | 21:45 |
| corvus | (incidentally, the openstack tenant is up to 134 configuration errors) | 21:51 |
| clarkb | corvus: to make sure I understand this process correctly: in _cacheTenantYaml | 21:55 |
| clarkb | er in _cacheTenantYAML we check if the cache is valid. If it is then we update from the cache without updating anything. but in your digging above we're hitting the cached data is invalid path so we go through cat jobs and then update the cache with the cat jobs? | 21:56 |
| corvus | clarkb: no, i'm working on a different end -- i started with "why are we seeing an error which doesn't belong to this change" as opposed to "where did the error come from". i think i have a theory as to the first question, but i don't have any theory or data about the second one. i think you're on the right path and i'll get there. i'm just following the breadcrumbs one at a time :) | 21:58 |
| clarkb | gotcha | 21:58 |
| corvus | (as an aside, i just saw in the logs a cooperative reconfiguration -- the first scheduler reconfigured the tenant and started re-enqueing changes in check; the second scheduler updated its configuration to match, saw that check was busy, and started re-enquing changes in gate) | 22:00 |
| clarkb | I should buy a dry erase board | 22:10 |
| corvus | i just extracted all the relevant log lines from a reconfiguration from an event versus one from a layout update, and they are exactly the same except that the first one from the event submits a cat job for the project-branch that triggered the event, and the second one only uses the cache. | 22:10 |
| corvus | so that's as expected. | 22:10 |
| clarkb | I'm wondering if UnparsedBranchCache's .get() method could potentially be adding things somehow. But thats mostly based on that seems to be where we get the parsed yaml but unprocessed for zuul data from and it has a fairly complicated set of logic for returning all the files | 22:15 |
| clarkb | like maybe https://opendev.org/zuul/zuul/src/branch/master/zuul/model.py#L7288-L7290 needs a dedeup step, But reading through it I haven't seen anything that would indicate generation of duplicates in that list yet | 22:17 |
| clarkb | The function starts with a list of unique fns because they are dict keys which must be unique | 22:18 |
| corvus | another clue: vexxhost tenant defines a nodeset with the same name | 22:20 |
| fungi | ooh, cross-tenant config leak? | 22:20 |
| clarkb | I think it is possible to set extra-config-paths that overlap with the defaults and double load | 22:22 |
| clarkb | but you'd have to explicitly set that config and then the change shouldn't merge because you'd haev duplicates there | 22:22 |
| clarkb | Basically it is possible to generate this error via a change that updates extra-config-paths but it shouldn't be mergeable | 22:23 |
| corvus | extra-config-paths is a tenant configuration setting (ie main.yaml) | 22:23 |
| clarkb | ah, but even then we'd notice separately I think. But ya since https://opendev.org/zuul/zuul/src/branch/master/zuul/model.py#L7282-L7289 isn't filtering for duplicates you could accidentally but intentionally add them in | 22:24 |
| clarkb | and opendev doesn't currently set extra-config-paths dups that I can see | 22:24 |
| clarkb | that is a long winded way of saying I think this is a problem but only in the general case and isn't currently the issue we are obvserving | 22:25 |
| corvus | agreed | 22:28 |
| clarkb | I need to take a break. Back in a bit | 22:31 |
| opendevreview | Ian Wienand proposed openstack/diskimage-builder master: containerfile: handle errors better https://review.opendev.org/c/openstack/diskimage-builder/+/817139 | 22:32 |
| opendevreview | Ian Wienand proposed openstack/diskimage-builder master: centos 9-stream: make non-voting for mirror issues https://review.opendev.org/c/openstack/diskimage-builder/+/817312 | 22:32 |
| opendevreview | Ian Wienand proposed openstack/diskimage-builder master: Revert "centos 9-stream: make non-voting for mirror issues" https://review.opendev.org/c/openstack/diskimage-builder/+/817313 | 22:32 |
| corvus | clarkb: okay, i found a difference between the schedulers... i'm manually running through createDynamicLayout, and in my simulation of this method, i get 386 nodesets on one scheduler, and 755 on the other: https://opendev.org/zuul/zuul/src/branch/master/zuul/configloader.py#L2482 | 22:41 |
| clarkb | is this through the repl? | 22:42 |
| corvus | ya | 22:42 |
| corvus | i think we can assume that at any given time, one scheduler has done a real tenant reconfiguration, the other has done the layout-update style reconfig | 22:43 |
| clarkb | oh interesting that method does a similar thing to the cache get() method I called out | 22:44 |
| corvus | in this case, the scheduler with 755 nodesets is the one that did the layout update. so the scheduler that did the real reconfiguration is in good shape, but the other one has too many nodesets | 22:45 |
| corvus | there are 2 ubuntu-bionic-2-node nodesets in the list; they're both from the same source_cnotext, so i don't think we're looking at a cross-tenant issue | 22:51 |
| corvus | they are different objects fwiw | 22:51 |
| corvus | i think i'm going to start working on a test case now | 22:52 |
| clarkb | its not surprising they are different objects due to config.extend(self.tenant_parser.parseConfig(tenant, incdata, loading_errors, pcontext)) | 22:53 |
| clarkb | we create a new object each time we view the file. I strongly suspect that somehow the same file (via same source_context) is getting loaded multiple times via ^ | 22:53 |
| clarkb | corvus: maybe double check that we don't have dups in tenant.untrusted_projects? | 22:58 |
| corvus | k | 23:01 |
| clarkb | and the other check would be tpc.branches doesn't have master listed twice I think | 23:01 |
| corvus | negative on both | 23:03 |
| clarkb | I guess that is good in that we're giving the method what should be correct inputs | 23:04 |
| corvus | the duplicate data is in tpc.branches | 23:04 |
| clarkb | corvus: is master listed multiple times? | 23:04 |
| corvus | ie, tpc.parsedbranchconfig.get('master').nodesets is long | 23:04 |
| corvus | nope | 23:04 |
| clarkb | I see so single master branch for the tpc but that has duplicated the nodesets info | 23:04 |
| corvus | yep | 23:05 |
| clarkb | https://opendev.org/zuul/zuul/src/branch/master/zuul/configloader.py#L2401-L2407 may be the issue then? | 23:06 |
| clarkb | hrm but we set config to an empty ParsedConfig at the start which means we should only add things which haven't already been added? | 23:08 |
| corvus | i think (unless i messed up in my testing) that this already has the duplicated data: https://opendev.org/zuul/zuul/src/branch/master/zuul/configloader.py#L2404 | 23:09 |
| clarkb | https://opendev.org/zuul/zuul/src/branch/master/zuul/configloader.py#L1599-L1601 | 23:12 |
| clarkb | are we maybe mixing a project,branch specific cache with the entire cache contents? | 23:13 |
| clarkb | I think that may be what is happening on line 1601, which pollutes line 2404? | 23:14 |
| clarkb | hrm but we do filter by the project and then branch there. I'm so confused. I should probably let corvus write that test case and fiugre it out | 23:18 |
| fungi | infra-prod-remote-puppet-else has started failing when trying to install pymysql on health01.openstack.org | 23:21 |
| clarkb | fungi: maybe we stick it in the emergency file and send an email to the list following up with the initial thread on turning that sutff off saying things are starting to break now? | 23:22 |
| fungi | not sure why it's just started, but pymysql requires python>=3.6 for some time now (it's last release was in january), and that's a xenial host so only has 3.5 | 23:23 |
| clarkb | we wouldn't update the installation unless the repo updated. I'm guessing the openstack-health repo updated? | 23:24 |
| fungi | oh, and it's trying to install it with python 2.7 anyway | 23:24 |
| fungi | Using cached https://files.pythonhosted.org/packages/2b/c4/3c3e7e598b1b490a2525068c22f397fda13f48623b7bd54fb209cd0ab774/PyMySQL-1.0.0.tar.gz | 23:25 |
| fungi | apparently 1.0.0 was yanked from pypi | 23:25 |
| fungi | yeah, looks like there's been some occasional updates merged to the openstack-health repo | 23:26 |
| fungi | most recent change merged 5 days ago | 23:27 |
| fungi | but infra-prod-remote-puppet-else has been succeeding until just now | 23:27 |
| ianw | how about i add another mystery | 23:34 |
| ianw | https://opendev.org/openstack/diskimage-builder/src/branch/master/diskimage_builder/elements/containerfile/root.d/08-containerfile#L63 | 23:34 |
| ianw | seems to me we have not been setting DIB_CONTAINERFILE_PODMAN_ROOT=1 in production | 23:34 |
| fungi | i've moved health01.openstack.org:/root/.cache/pip out of the way to see if it works when rerun | 23:34 |
| ianw | meaning that "tar -C $TARGET_ROOT --numeric-owner -xf -" was not running as root, but yet seemingly somehow still managing to write everything as root owned? | 23:35 |
| ianw | this is not working now. i can't quite understand how it was ever working | 23:35 |
| clarkb | ianw: podman will use user namespacing where you can be root in the container but normal user outside of the container | 23:35 |
| clarkb | could that explain it? | 23:35 |
| ianw | this is a tar outside any podman context | 23:36 |
| clarkb | oh I see it is the tar on the other end of the podman export pipe | 23:37 |
| clarkb | and we aren't setting the flag to prepend with sudo hence the confusion | 23:38 |
| clarkb | are we running dib with privileges so that any process ti forks gets them too? | 23:39 |
| ianw | in the gate tests, we set that flag https://opendev.org/openstack/diskimage-builder/src/branch/master/roles/dib-functests/tasks/main.yaml#L69 | 23:39 |
| corvus | clarkb: i have been unable to reproduce in a test case so far. i started 2 schedulers, forced a reconfig on one, then let the other scheduler handle a patchset upload of a .zuul.yaml... no duplicate nodesets. :/ | 23:40 |
| ianw | ok, it's my fault | 23:41 |
| ianw | https://review.opendev.org/c/openstack/diskimage-builder/+/814081/13/diskimage_builder/elements/containerfile/root.d/08-containerfile | 23:41 |
| clarkb | ianw: ah it was a hardcoded sudo previously | 23:41 |
| ianw | that it got 7 reviews and nobody noticed makes me feel *slightly* better that it was subtle :) | 23:42 |
| clarkb | corvus: back to the repl I guess? I don't really have any better ideas than somehow that loop is likely to be injecting extra data because we aren't careful against duplicates | 23:45 |
| fungi | spot checks indicate the iptables reject rule change rolled out without problem | 23:50 |
| fungi | REJECT all -- anywhere anywhere reject-with icmp-admin-prohibited | 23:50 |
| clarkb | cool maybe we can land https://review.opendev.org/c/opendev/system-config/+/816869 tomorrow if frickler and ianw get a chance to review it "overnight" (relative to me) | 23:52 |
Generated by irclog2html.py 2.17.2 by Marius Gedminas - find it at https://mg.pov.lt/irclog2html/!
{kind=link}