| frickler | fwiw I've seen that apache restart issue before, but didn't look into a solution yet | 08:12 |
|---|---|---|
| opendevreview | Merged zuul/zuul-jobs master: Add upload-image-swift role https://review.opendev.org/c/zuul/zuul-jobs/+/944812 | 10:22 |
| opendevreview | Merged zuul/zuul-jobs master: Add upload-image-s3 role https://review.opendev.org/c/zuul/zuul-jobs/+/944813 | 10:22 |
| opendevreview | Fabien Boucher proposed zuul/zuul-jobs master: zuul_log_path: allow override for emit-job-header and upload-logs https://review.opendev.org/c/zuul/zuul-jobs/+/943586 | 11:06 |
| opendevreview | Fabien Boucher proposed zuul/zuul-jobs master: zuul_log_path: allow override for emit-job-header and upload-logs https://review.opendev.org/c/zuul/zuul-jobs/+/943586 | 11:10 |
| opendevreview | Fabien Boucher proposed zuul/zuul-jobs master: zuul_log_path: allow override for emit-job-header and upload-logs https://review.opendev.org/c/zuul/zuul-jobs/+/943586 | 11:13 |
| mnasiadka | clarkb, fungi : I'd like to thank whoever fixed the aarch64 nodes to be fast again :) | 11:54 |
| Clark[m] | mnasiadka we redeployed the mirror and nodepool builder in osuosl and noticed they were quick. We didn't change anything on our end so must've been Ramereth[m] | 13:37 |
| fungi | clarkb: the python3.13.2t is a pyenv bug where it's selecting a free-threading build of python because that looks like the highest "version number" | 13:45 |
| Clark[m] | Ya I remembered you pushed a workaround to zuul-jobs that I thought had merged (it hasn't). I need to depends on that and revert my python version selector | 13:47 |
| corvus | loooks like we have zuul-launcher image builds for all the clouds: https://zuul.opendev.org/t/zuul/image/debian-bullseye | 14:40 |
| corvus | i think that page could probably use a column showing the format for each of the build artifacts. but reading between the lines, it looks like ovh and raxflex use qcow2 and vexxhost and openmetal use raw? does that sound right? | 14:41 |
| corvus | then we have two builds for each of those (current and previous) | 14:41 |
| clarkb | corvus: looking at our nodepool builder config our base default is qcow2 so then only clouds that override that would get raw or vhd | 14:42 |
| clarkb | so I think that is about right. vexxhostand openmetal use ceph to back the disks and ceph doesn't play as well with qcow2 as it does with raw | 14:43 |
| clarkb | doubling up on the copy on right stuff doesn't work | 14:43 |
| clarkb | so ya that lgtm | 14:43 |
| corvus | ah that's why. i wondered. :) | 14:43 |
| clarkb | *copy on write | 14:46 |
| clarkb | infra-root how do we feel about upgrading gitea today to the latest bugfix release: https://review.opendev.org/c/opendev/system-config/+/945414 fungi has +2'd the change and screenshots lgtm : https://storage.gra.cloud.ovh.net/v1/AUTH_dcaab5e32b234d56b626f72581e3644c/zuul_opendev_logs_ed2/openstack/ed2d3a106d304d57ace4a9c901c12bac/bridge99.opendev.org/screenshots/ | 14:59 |
| clarkb | the main consideration is probably the openstack release next week | 14:59 |
| clarkb | I'm getting my morning started but I expect to be around until thunderstorms knock out my power (and I hope that doesn't happen). But that isn't expected until this afternoon so I think I'm good with it | 15:04 |
| fungi | this seems like a fine time for a gitea bugfix point release upgrade | 15:05 |
| fungi | i'm around to help test | 15:05 |
| clarkb | ok I'll give it a few more minutes for feedback then can hit +A | 15:07 |
| clarkb | I approved it | 15:15 |
| frickler | a week until the openstack release should be fine to find any possible issues and fix them if needed, but I agree the risk seems low, too | 15:28 |
| clarkb | ya if this was an upgrade to 1.24 I would wait | 15:30 |
| opendevreview | Dr. Jens Harbott proposed openstack/project-config master: Cap max-servers for rax clouds https://review.opendev.org/c/openstack/project-config/+/945623 | 15:30 |
| clarkb | but 1.23.5 to 1.23.6 should be much safer | 15:30 |
| frickler | infra-root: ^^ that's my proposal to see if it helps with the timeouts I mentioned yesterday, let me know what you think | 15:30 |
| clarkb | +2 from me | 15:31 |
| clarkb | seems like an easy safe experiment | 15:31 |
| clarkb | frickler: my zuul python 3.13 test job is very slowly running pip install for requirements. I jumped on that test node 104.130.253.199 and it is almost idle. The problem seems to be with io to/from the mirror? | 15:38 |
| clarkb | frickler: might be worth checking if the mirror is being overwhelmed or has some other issues. In the past we noticed similar slowness which was mitigated by switching to the internal rax network interfaces. But maybe now those internal interfaces are having problems. I don't know just noting what I observe | 15:39 |
| clarkb | of course reducing total test nodes would reduce demand on the mirrors if they are overwhelmed that would still help | 15:40 |
| fungi | could be ai crawlers | 15:40 |
| clarkb | ha yes why didn't I consider that | 15:42 |
| Ramereth[m] | <Clark[m]> "mnasiadka we redeployed the..." <- I did make some changes in the backend storage, glad you noticed an improvement! Can you say how much of an improvement it was? | 15:47 |
| mnasiadka | Ramereth[m]: previously kolla build jobs timed out after 2.5/3 hours - now they finish in like 30-40 minutes :) | 15:47 |
| Ramereth[m] | sweet, are they using ephemeral disks for the VMs? | 15:48 |
| clarkb | Ramereth[m]: we're usingthe opendev.large flavor however that boots | 15:50 |
| clarkb | for our image builder node we use a persistent volume and buidls went from several hours to around an hour | 15:50 |
| Ramereth[m] | clarkb: yeah, so I added additional SSD nodes to Ceph and migrated that pool over to SSD. I also reduced the replication from 3 to 2 to save space needed to use SSD's | 15:51 |
| clarkb | it seems to have helped | 15:52 |
| clarkb | re mirror.dfw system load is low and tailing some access logs I see lots of what I expect are normal pip requests | 15:53 |
| clarkb | dnf is requesting centos 9 packages over port 80 and not 443 | 15:53 |
| Ramereth[m] | clarkb: btw did something happen to nl01.opendev.org? I had a nagios check to see when we had any images we needed to manually cleanup but it's no longer working | 15:54 |
| clarkb | Ramereth[m]: oh sorry I deleted it and nl05.opendev.org took its place | 15:55 |
| clarkb | it didn't occur to me that external users may be using those in automated checks. But if you just update the hostname in the fqdn it should go back to working | 15:55 |
| clarkb | (I've been working through server replacements to update their base OSes) | 15:55 |
| clarkb | doing a bigger tail -f dragnet on mirror.dfw I don't see anything that looks like obvious ai web crawler traffic | 15:56 |
| Ramereth[m] | <clarkb> "Ramereth: oh sorry I deleted..." <- Confirmed this is working again, thanks! | 16:02 |
| clarkb | and good luck with the storms today | 16:06 |
| Ramereth[m] | Yeah, I hope it won't be bad | 16:07 |
| clarkb | I managed to get half the garage cleared out so the car can move inside today. | 16:07 |
| frickler | clarkb: yes, I suspected either network or disk io. for kolla the timeouts mostly happen while pulling container images via the mirror node | 16:23 |
| opendevreview | Thierry Carrez proposed opendev/irc-meetings master: Move Large Scale SIG meeting one hour earlier https://review.opendev.org/c/opendev/irc-meetings/+/945633 | 16:36 |
| clarkb | one thought I had is maybe afs is slow but load average on the afs server looks ok and we see slowness pulling from pypi too which doesn't involve afs | 17:25 |
| clarkb | so ya this is kinda pointing at some sort of io (network and/or disk) slowness in rax I think | 17:26 |
| fungi | container images aren't coming from afs either right? | 17:26 |
| clarkb | no. Only distro packages | 17:26 |
| *** iurygregory_ is now known as iurygregory | 17:26 | |
| clarkb | I think it is possible that afs is impacted by the same io issues but I suspect that it isn't the cause | 17:26 |
| clarkb | I think we should consider frickler's change to dial back use of rax and see if lower demand helps on the whole | 17:27 |
| fungi | yeah, but as i said yesterday this might also be an opportunity to ask about dialling up use of flex at the same time, essentially starting to shift capacity in that direction | 17:31 |
| clarkb | fwiw I did ask jamesdenton a little while ago and he said he wuold check. But haven't heard back on that yet. So I don'tw ant to push the issue | 17:32 |
| fungi | sure, that's totally fair | 17:33 |
| opendevreview | Merged opendev/system-config master: Update to Gitea 1.23.6 https://review.opendev.org/c/opendev/system-config/+/945414 | 17:33 |
| fungi | that ^ should start deploying straight away | 17:33 |
| clarkb | gitea09 is in the process of restarting now | 17:37 |
| fungi | yeah, i just got the "service unavailable" page for it | 17:37 |
| fungi | and it's back online now | 17:38 |
| clarkb | https://gitea09.opendev.org:3081/opendev/system-config/ confirmed | 17:38 |
| fungi | Powered by Gitea Version: v1.23.6 | 17:38 |
| clarkb | git clone works for me too | 17:38 |
| clarkb | 10 is upgraded now too | 17:40 |
| clarkb | jamesdenton: re the conversation above we've seen jobs in rax classic (particularly dfw but maybe in iad and ord) become very slow. Initial investigation appears to show most of the time "lost" is performing network IO to grab things like python packages through our local caching proxy to pypi.org. But also through the cache proxy to quay (I think kolla is using quay now and not | 17:43 |
| clarkb | docker hub) | 17:43 |
| clarkb | jamesdenton: not sure if old rax is something you have insight into, but figured we'd pass that along. | 17:43 |
| fungi | deploy succeeded | 17:48 |
| fungi | all backends should be on 1.23.6 now | 17:48 |
| clarkb | they appear to be from my checks | 17:49 |
| clarkb | I guess the last thing to check is replication. I'm looking for a new patchset that has been pushed since 17:48 to check wtih | 17:56 |
| jamesdenton | thanks clarkb. We are also seeing a few reports of slowness in another application, so it's on my list. In terms of bumping quota for Flex, i will start a thread for that | 17:56 |
| clarkb | jamesdenton: thanks. Let us know if we can help with the debugging. | 17:57 |
| clarkb | no new patchsets yet /me looks to see if any changes need a new patchset | 17:58 |
| jamesdenton | clarkb are your resources primary in DFW? | 18:00 |
| clarkb | jamesdenton: we notice most of the slowness in CI jobs which are in dfw, iad and ord. But many of our control plane services do run in dfw primarily including zuul and nodepool that coordinate all of the test resources | 18:01 |
| jamesdenton | gotcha | 18:01 |
| jamesdenton | clarkb if you come across one again, let me know if it's possible to login an tshoot | 18:03 |
| clarkb | jamesdenton: sure let me see if I can find one | 18:03 |
| clarkb | jamesdenton_: I asked nodepool to hold (not delete) the nodes for https://zuul.opendev.org/t/openstack/stream/60e83b5589fb47efa47e6d819debbe76?logfile=console.log but it will only do so if the job fails. If you open up that link you'll see it taking almost 2 minutes to download a 41MB package | 18:12 |
| clarkb | of course the problem may be elsewhere still but starting with what we know and trying to work from there | 18:13 |
| clarkb | the server is named np0040280911 with ip address 23.253.108.101 | 18:13 |
| clarkb | I guess I can hop on the server and run a speedtest when the job is done assuming it fails | 18:13 |
| clarkb | and try to see if we can isolate the slowness | 18:14 |
| fungi | i suppose you could sabotage the running build carefully to trigger the autohold while causing zuul to retry it | 18:16 |
| fungi | maybe surgically kill an ssh connection from the executor or something | 18:17 |
| clarkb | I thought about that but the job us running at the top of the gate | 18:17 |
| clarkb | another option would be to just boot a test node manually | 18:17 |
| jamesdenton_ | i can boot a node, no problem | 18:18 |
| clarkb | anyway I don't want to force that one to fail if it will otherwise succeed | 18:18 |
| jamesdenton_ | i will add this to the list :) | 18:18 |
| fungi | got it | 18:18 |
| fungi | though if you can cause a retry that shouldn't reset the gate queue, just delay it | 18:19 |
| clarkb | true. I guess the trick is in being confident you'll cause a retry and not a failure | 18:19 |
| jamesdenton_alt | 2025-03-26 17:59:11.511852 | compute1 | Fetched 166 MB in 8min 18s (333 kB/s) | 18:19 |
| jamesdenton_alt | i'm guessing that's not reasonable? | 18:19 |
| jamesdenton_alt | my irc bouncer is boucing, sorry. | 18:20 |
| clarkb | ya I think the slowness is those fetches. At first I suspected that openafs may be the problem (those packages are on an openafs filesystem also hosted in dfw) but it appears that fetches for pypi packages through our mirror is also slow and that is a pass through caching proxy to pypi.org | 18:20 |
| clarkb | it could be that the mirror itself is a problem but system load there aws reasonable and my checks for ai web crawlers didn't show that being a problem | 18:21 |
| clarkb | but I suppose if the mirror specifically had networking io trouble that would be felt across many/most/all of the tests | 18:21 |
| clarkb | the mirror is mirror02.dfw.rax.opendev.org | 18:22 |
| fungi | dmesg also doesn't indicate any recent incidents on it | 18:22 |
| jamesdenton_alt | and that's a mirror you manage? 10.208.224.195? | 18:23 |
| fungi | correct, job nodes are communicating with it across the 10.x network for better performance | 18:23 |
| jamesdenton_alt | the 10.x "servicenet" network? | 18:24 |
| fungi | but it's also globally reachable at 104.130.140.186 | 18:24 |
| clarkb | though mirror-int.dfw.rax.opendev.org isn't resolving for me right now | 18:24 |
| clarkb | I thought we put that in public dns | 18:24 |
| fungi | resolves for me | 18:24 |
| jamesdenton_alt | i resolved to a cname - mirror02-int.dfw.rax.opendev.org. | 18:24 |
| fungi | $ host mirror-int.dfw.rax.opendev.org | 18:24 |
| fungi | mirror-int.dfw.rax.opendev.org is an alias for mirror02-int.dfw.rax.opendev.org. | 18:24 |
| fungi | mirror02-int.dfw.rax.opendev.org has address 10.208.224.195 | 18:25 |
| clarkb | ya this must be a local dns problem | 18:25 |
| clarkb | if I dig against google it resolves | 18:25 |
| fungi | hopefully we haven't broken dnssec signatures for that | 18:25 |
| clarkb | but ya that is a node that lives in dfw to serve as a cache for resources that test jobs consume. It caches pypi packages, container image layers, and distro packages | 18:25 |
| fungi | though if we had, i shouldn't be able to resolve it either | 18:25 |
| clarkb | ya I think its more likely that my over complicated ad blocking rules are tripping on it for some reason | 18:26 |
| jamesdenton_alt | i wonder if things improve over that public interface vs snet interface... hmm | 18:27 |
| clarkb | jamesdenton_alt: the reason we use the internal network is we had similar problems a few yaers ago at this point over the public network | 18:27 |
| clarkb | switching to the private network addressed it | 18:27 |
| jamesdenton_alt | of course. lol | 18:27 |
| clarkb | but its possible the other way around is true now | 18:27 |
| fungi | i think it was qos forcing different limits on the global side | 18:28 |
| jamesdenton_alt | possible | 18:28 |
| clarkb | on that mirror if I wget https://cloud-images.ubuntu.com/noble/current/noble-server-cloudimg-amd64.img I get 28.9MB/s | 18:28 |
| fungi | the flavor-based network rate limiting was a little janky, if memory serves | 18:28 |
| clarkb | that would go over the public network | 18:28 |
| clarkb | and seem to be much quicker | 18:29 |
| clarkb | so ya maybe something to do with the private networking? | 18:29 |
| fungi | we should be able to test across the 10.x address from one of our control-plane servers in that region | 18:29 |
| jamesdenton_alt | yeah, it's possible there's an issue with the servicenet network, somewhere | 18:29 |
| clarkb | reminds me of that time infracloud's switch became a hub | 18:30 |
| jamesdenton_alt | that sounds like a bad time. | 18:31 |
| clarkb | let me try something like scp'ing that image file over the service net between rax-dfw nodes | 18:31 |
| clarkb | I'm downloading it again to get more datapoint first | 18:32 |
| clarkb | second time was 29.0MB/s | 18:32 |
| clarkb | so that is consistent | 18:32 |
| clarkb | currently getting just above 400KBps | 18:33 |
| fungi | ideally try to grab something via https, since traffic shaping might impact througput differently for each protocol | 18:34 |
| clarkb | sure but we already have data that that is slow | 18:34 |
| clarkb | and this way I can show that it isn't our http service | 18:34 |
| fungi | oh, right | 18:34 |
| clarkb | now down to 200KB/s or so | 18:34 |
| clarkb | so ya this seems like an internal network is super slow for some reason problem. | 18:35 |
| fungi | though we do have other webservers listening on 10.x in that region too | 18:35 |
| fungi | but if you can reproduce it with scp too then good enough | 18:35 |
| jamesdenton_alt | is this between the mirror and other hosts? | 18:35 |
| clarkb | I'm running the scp from paste.opendev.org to mirror.dfw.rax.opendev.org over the internal network address | 18:35 |
| fungi | so yes | 18:36 |
| fungi | might also try between e.g. paste and codesearch or something, to see if it's impacting other hosts besides mirror.dfw.rax | 18:37 |
| clarkb | ack let me cancel this download as it seems we have enough data here so far | 18:37 |
| clarkb | codesarch got 33MB/s pulling from ubuntu | 18:38 |
| clarkb | paste scp'ing from codesearch got 85.9MB/s | 18:39 |
| clarkb | so seems more specific to the mirror node (or maybe its network etc) | 18:39 |
| fungi | so one possibility (cacti is not easy to check at the moment) is we're simply maxing out the bandwidth quota for the internal interface of the mirror server | 18:42 |
| fungi | another is maybe noisy neighbor on the same compute host choking the physical interface (not sure what the wired topology looks like there so hard to guess) | 18:43 |
| clarkb | or something occuring at the switch level too | 18:43 |
| clarkb | fetching things over the public interface is speedy so I don't think the server itself is sad. This seems isolated to that specific network | 18:43 |
| fungi | but given that the prior observations were this only occurred at times of peak utilization for job resources, that would fit with interface rate limits | 18:44 |
| clarkb | I went ahead and deleted the noble image from all three nodes so that its not consuming disk space unnecessarily | 18:44 |
| clarkb | its also possible we only notice during those times because there are so many more jobs running during those periods | 18:45 |
| fungi | maybe this has only become an issue lately because some jobs have started to pull more content through our mirrors | 18:45 |
| fungi | and that's started to push us over some rate limit | 18:45 |
| fungi | i'll see if i can get a port forward up to check cacti | 18:46 |
| jamesdenton_alt | clarkb fungi i will dig around and see what qos policies might be applied to servicenet interfaces, and if i can find the hypervisor, i'll check the stats | 18:48 |
| fungi | thanks jamesdenton_alt! | 18:48 |
| clarkb | ++ | 18:48 |
| fungi | argh, i think my ff may dislike the ssl options on the cacti server now | 18:53 |
| clarkb | the unfortunate thing with network trouble like this it can be so many things. Maybe interfaces renegotiated at 10mbps for some reason. Or switch is acting like a hub because arp caches are full. Or qos rules are unexpectedly taking effect. Or we've got significant packet loss impacting window sizes so they never grow beyond a very minimal value | 18:53 |
| fungi | oh, conveniently, the cacti server doesn't redirect http to https | 18:54 |
| clarkb | fun story. In a previous life I was a network person and some team couldn't figure out why microsoft ftp server was terribly slow. Turns out that the implementation at the time used an incredibly small window size which meant and downloads beyond like half a ms of rtt would always be terribly slow | 18:54 |
| clarkb | that was a really fun one to debug because testing it in the datacenter it was always fine | 18:55 |
| clarkb | the workaround was you could edit the registry to increase the window size because of course | 18:56 |
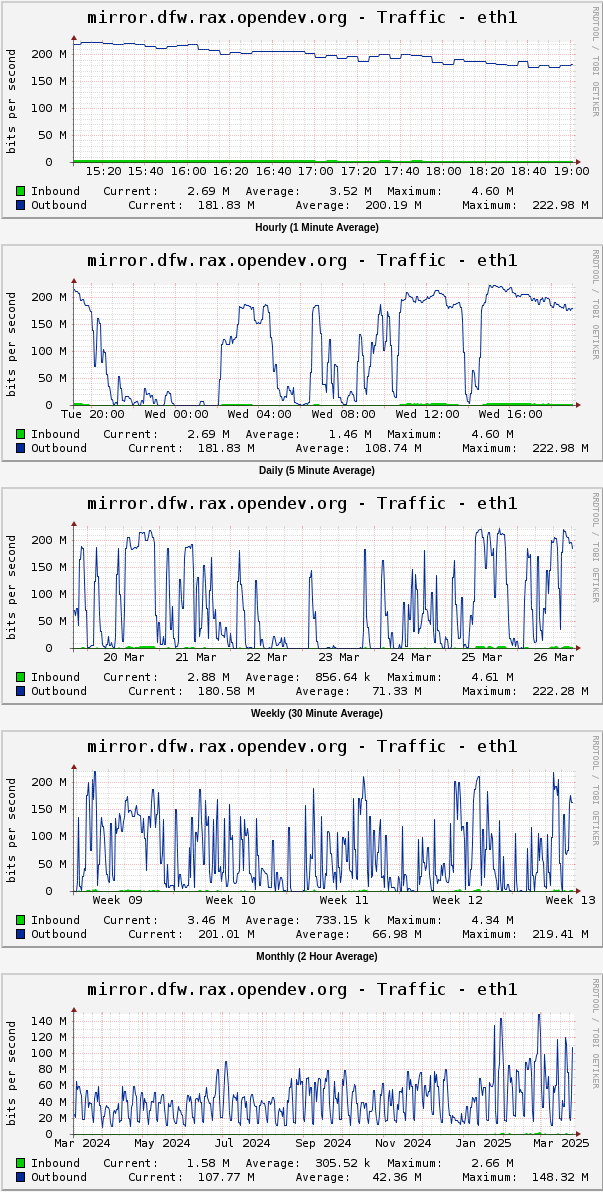
| fungi | eth1 traffic does look like it's topping out in weird ways around 200Mbps | 18:56 |
| clarkb | and historically I'm guessing it didn't do that? | 18:56 |
| clarkb | either beacuse we were always under that limit or because we were well over it? | 18:57 |
| clarkb | I need to pop out for lunch now. Back in a bit | 18:57 |
| fungi | trying to get to the longer-term graphs | 18:57 |
| fungi | here we go: https://fungi.yuggoth.org/tmp/dfw-mirror-traffic.png | 19:11 |
| fungi | so for the past ~2 months we've been seeing about double the bandwidth utilization as we did all last year | 19:11 |
| Clark[m] | My tails of Apache logs didn't show anything that stood out to me as abnormal or wrong but there is a lot of it which may be worth checking. Another thought is I got 85MB/s between nodes on private networks which is much greater than 200mbps | 19:14 |
| Clark[m] | It could be possible that whatever problem here has us keeping connections open longer so that snmp records it? Whereas before we'd have shorter much smaller blips? | 19:14 |
| fungi | well, again, this is specifically on the internal 10.x interface (eth1) so is unlikely to be a scraper/bot | 19:15 |
| Clark[m] | 85* 8/200 is about 3.5x more throughout | 19:15 |
| Clark[m] | True | 19:15 |
| fungi | my money's on jobs pulling more container images or other large files from the cache | 19:16 |
| Clark[m] | Anyway 200mbps seems low to me as a cap given the speed I got between codesearch and paste | 19:16 |
| fungi | maybe in response to dockerhub issues | 19:16 |
| Clark[m] | So even if there is more data passing here th cap seems unusually low | 19:16 |
| fungi | some rate-limiting mechanisms have a bit of a delay to kick in, too | 19:17 |
| fungi | though the server is using performance1-8 which claims to have rxtx_factor=1600.0 | 19:17 |
| fungi | which i think is supposed to be Mbps? | 19:18 |
| fungi | but maybe it doesn't apply the same limits on the internal network either | 19:18 |
| Clark[m] | We can drop the use of -int interfaces and see what happens | 19:19 |
| jamesdenton_ | mind PM'ing me the UUID of the VM? | 19:19 |
| fungi | even adding the eth0 and eth1 inbound+outbound traffic together it's nowhere near 1600Mbps. maybe 20% of it at most | 19:20 |
| jamesdenton_ | thanks fungi | 19:21 |
| Clark[m] | 200mbps is suspiciously similar to lacp over two 100mbps links. But I have no knowledge of the interface setup on the hypervisors | 19:23 |
| fungi | well, the graphs do show peaking over 200 and then getting squeezed back down, which is typical behavior for some traffic shapers | 19:24 |
| fungi | there's often a bit of a delay before the rate limiting kicks in | 19:25 |
| fungi | oh, i already said that | 19:25 |
| fungi | anyway, if it was a 2x100 bond or something i'd expect it to look more like a hard limit | 19:25 |
| fungi | which this doesn't | 19:26 |
| opendevreview | Clark Boylan proposed openstack/project-config master: Stop using the -int interface on rax mirrors https://review.opendev.org/c/openstack/project-config/+/945651 | 19:51 |
| clarkb | thats maybe the nuclear option. We could do a setup where only dfw doens't use -int | 19:51 |
| clarkb | but I figure consistency is a good thing if we want to make the change so went with the rip it out option instead | 19:51 |
| corvus | clarkb: the traffic graphs should be based on interface byte counters, so tcp session duration shouldn't affect it (they should be counting everything). | 19:57 |
| clarkb | ah so that value is the 5 minute average for the interface | 19:58 |
| fungi | right, snmp checks the interface to see the bytes tx and rx totals, then 5 minutes later it checks them again and subtracts the previous values | 19:58 |
| clarkb | and not a point in time | 19:58 |
| fungi | so yes effectively a ~5-minute mean (there's a bit of jitter due to snmp request timing, but not enough to be more than statistical noise) | 19:59 |
| fungi | trying to infer rate limiters from such readings is sort of a gut feel thing, because the mean represents the minimum possible for a spike within that timeframe, so you have to assume there were probably points between where it went higher, though you can't really know by how much | 20:02 |
| fungi | in some cases rate limiters exhibit a sort of hysteresis, if the period is longer than the sample duration it can even be visible as a harmonic | 20:04 |
| clarkb | I think our options are: see if jamesdenton_ finds anything wrong with the network, land https://review.opendev.org/c/openstack/project-config/+/945651 and use a different network, or reduce the total test nodes to reduce overall demand, or some combo of the three | 20:04 |
| clarkb | I did briefly consider multiple mirrors using A/AAAA dns round robins too | 20:04 |
| clarkb | but that seems liek a lot of effort for now. That may become an option in the future though | 20:04 |
| fungi | that would probably work well enough too, yeah | 20:04 |
| clarkb | I do think that letting things run in sad mode is not ideal so at the very least we should probably land https://review.opendev.org/c/openstack/project-config/+/945623 | 20:05 |
| clarkb | and if that doesn't help proceed with the switch to public interfaces? | 20:06 |
| clarkb | or just do both and send it | 20:06 |
| fungi | for now, i've approved 945623 to temporarily lower our use of rackspace classic | 20:09 |
| fungi | if this is bandwidth contention, it will likely have the desired effect | 20:10 |
| corvus | heh i would have started with 651 | 20:16 |
| corvus | because if 651 fixes it, then we're in an optimal state. if 623 fixes it, we're suboptimal and we still have work to do (ie, land 651) | 20:16 |
| opendevreview | Merged openstack/project-config master: Cap max-servers for rax clouds https://review.opendev.org/c/openstack/project-config/+/945623 | 20:17 |
| corvus | not a problem, just that we're guaranteed to need another patch after 623 | 20:17 |
| fungi | my main concern is that 945651 could make things worse | 20:20 |
| fungi | given we don't yet know the cause | 20:20 |
| fungi | whereas with 945623 we can at least pretty confidently guess a minimum bound on how much worse that will be | 20:21 |
| fungi | er, maximum bound | 20:22 |
| clarkb | accessbot, matrix eavesdrop, and limnoria are all up next for python 3.12. Have a preference for which one goes first? maybe matrix eavesdrop? I think the impact there is pretty low since matrix has logs too | 20:23 |
| fungi | and per my review comment, it could actually improve throughput if it results in fewer job timeouts and rechecks | 20:23 |
| fungi | accessbot should have the least impact, it's not really continuously used | 20:24 |
| fungi | it really only matters if someone adds/changes its configs | 20:25 |
| fungi | maybe after it updates, we could solicit another chanop volunteer and test adding them | 20:26 |
| clarkb | wfm I can +A that change now | 20:26 |
| clarkb | done | 20:26 |
| corvus | fungi: i don't think lowering overall capacity is acceptable long-term. it may improve throughput on one project but at the cost of others. | 20:28 |
| corvus | so what's the next step after observing 623? if it makes things better, i don't think we can leave it there. we need to find a better fix, so i'd popose that if it does make things better, we revert it and see if 651 fixes things. | 20:30 |
| corvus | (and then, if 651 fails to make things as good as 623, we put 623 back and regroup) | 20:30 |
| clarkb | that sounds reasonable to me | 20:30 |
| fungi | well, my hope was that we hear back as to what the actual cause of the problem is, and then either restore the missing capacity in those regions or get equivalent capacity in flex | 20:32 |
| corvus | an external fix would be ideal, yes | 20:33 |
| fungi | if it really is some sort of aggregate network capacity limit we're running up against, then either it can be fixed within the provider or it can't, and if it can't then we may need to look at other options for reducing our bandwidth utilization for that mirror (clarkb's suggestion of dns round-robin between two mirror servers in each region seems like a reasonable solution there) | 20:34 |
| fungi | my current supposition as to why throughput on eth0 is good and throughput on eth1 is bad is that the graphs show comparatively little contention for eth0 at the moment, but if we shift all our traffic from eth1 to eth0 then i see a few possible outcomes: | 20:36 |
| fungi | 1. the rate limit on eth0 is the same as it is on eth1... this will make matters worse because now we're adding the already existing public traffic talking to pypi, dockerhub, etc together with the traffic to test nodes | 20:37 |
| fungi | 2. the rate limit is shared between eth1 and eth0... this will neither improve nor worsen performance (but it seems unlikely since under that model we should be seeing performance issues for eth0 already and aren't) | 20:38 |
| clarkb | I suspect that we won't make matters much worse if measured from a job success rate standpoint | 20:40 |
| fungi | 3. the rate limit on eth0 is higher than it is on eth1 (or whatever peformance issue impacting the host isn't effecting the physical path eth0 relies on)... this is the only scenario where i would expect 945651 to help | 20:40 |
| clarkb | would we prefer I update the project-config change to only modify dfw to reduce the blast radius? | 20:41 |
| corvus | (i'm assuming there's a 4: eth0 is lower than eth1, where 651 makes thing worse as well) | 20:41 |
| clarkb | I guess another option is to boot a new mirror and switch the current record to it alone | 20:42 |
| fungi | yeah, i mean there's a long tail of scenarios where things could get worse, i didn't want to enumerate them all ;) | 20:42 |
| clarkb | if the problem is iwth that specific hypervisor we have a good chance of alnding on a different hypervisor and the new mirror would be happier | 20:42 |
| corvus | i agree, i think 2 is unlikely and we can put it at the bottom of our list for when we've exhausted other hypotheses... | 20:42 |
| fungi | i can reestablish my port forward to cacti and see if iad and ord are exhibiting a similar traffic pattern on eth1 | 20:42 |
| clarkb | fungi: that would be helpful | 20:43 |
| corvus | maybe i should port-forward and take a look too | 20:43 |
| fungi | iad looks a lot healthier by comparison | 20:44 |
| fungi | i see traffic spiking more naturally and going up as high as 800Mbps at one point today | 20:44 |
| corvus | have we only noticed job problems in dfw? | 20:45 |
| clarkb | dfw jobs are definitelywhere I'ev noticed it | 20:45 |
| corvus | ord is spikey up to 500Mbps | 20:46 |
| fungi | ord also looks more like iad, with traffic spiking up as high as 700Mbps earlier in the week and 600Mbps when daily periodic jobs kicked off | 20:46 |
| corvus | i like the idea of booting a new mirror, in dfw only, seeing if it behaves better, and if so, switching to it, and if not, then round-robining with the existing one | 20:47 |
| fungi | i've been going off anecdotes and frickler's observations so far, it sounded like he thought all of rax classic was impacted, but if the anomalous eth1 traffic limiting i'm seeing on the graphs is tied to the cause then i would only expect dfw to be impacted | 20:47 |
| corvus | because unless someone says "oh ord and iad are failing jobs too" then this is looking like a dfw issue | 20:47 |
| corvus | all right | 20:49 |
| corvus | so what jobs are failing? | 20:49 |
| corvus | i need to know what to look up in zuul so i can figure out if this is dfw only or hits other regions | 20:49 |
| clarkb | kolla jobs, I think I had a zuul unittest job timeout. The job I put a hold on (not suer if it failed but I'll check) was a cinder grenade job | 20:49 |
| corvus | https://zuul.opendev.org/t/openstack/builds?project=openstack%2Fkolla&result=TIMED_OUT&skip=0 | 20:50 |
| corvus | something like that? | 20:50 |
| corvus | oh but maybe only tox jobs? | 20:50 |
| clarkb | ya I think this expresses itself as timeouts as pip install and apt-get install etc are what are particularly slow | 20:51 |
| fungi | overall the evidence i've seen so far was very slow download times in dfw jobs pulling content from dfw, probably jobs with low timeouts are more likely to get nudged over the edge from that | 20:51 |
| clarkb | the cinder job I put a hold on succeeded. It took 2 hours. | 20:51 |
| clarkb | fungi: yup | 20:51 |
| fungi | er, pulling content from the dfw mirror | 20:51 |
| fungi | in jobs with high timeouts due to expectation of longer runtimes for their tests, slow package downloads are more likely to be noise in the total duration | 20:52 |
| fungi | whereas for normally quick jobs they represent a more outsized proportion of the overall job runtime | 20:53 |
| corvus | okay, if we look at all the kolla jobs, it's not helpful. the distribution of timeouts looks like our cloud distribution. so i'll try looking just at tox jobs that timed out | 20:54 |
| fungi | though very quick jobs may show less incidence courtesy of us having a comparatively long default timeout too, so they can probably absorb slow package downloads | 20:54 |
| corvus | okay i don't know what to look for | 20:55 |
| fungi | i'd wager tox-based unit tests are in the sweet spot of being more likely to hover on the verge of their configured timeouts already | 20:55 |
| fungi | whereas linter jobs probably have so much headroom in the default timeout that they don't exceed it even with this problem | 20:55 |
| clarkb | I suspect the cacti data is enough info to focus on dfw | 20:56 |
| clarkb | and not overthink the analysis of which locations are affected | 20:56 |
| clarkb | we know dfw is affected. This seems reflected through job logs, direct testing, and cacti | 20:56 |
| fungi | https://zuul.opendev.org/t/openstack/builds?result=TIMED_OUT&skip=0 does show quite a few timed_out unit test jobs | 20:57 |
| corvus | there are no openstack-tox-py312 timeouts in openstack/kolla this year | 20:57 |
| clarkb | using cacti we can rule out the other two but have not done so with the othr two criteria | 20:57 |
| clarkb | given that I'm ahppy to update my change to select mirrors to only change things for dfw and then monitor. I'm also happy to spin up a new mirror in dfw under the assumption the old mirror is in a sad hardware state somehow and a new one is less likely to end up in the same situation | 20:59 |
| fungi | an openstack-tox-py312 example i just pulled up for neutron ran in ord: https://zuul.opendev.org/t/openstack/build/3ae2224e82eb49a3b41584f719dfe1f3 | 20:59 |
| fungi | random sample, maybe unrelated | 20:59 |
| corvus | fungi: yeah, good idea -- though i see basically everything except dfw in that list. based on that, i'd say we need to look at bhs1 | 20:59 |
| clarkb | fungi: https://zuul.opendev.org/t/openstack/build/3ae2224e82eb49a3b41584f719dfe1f3/log/job-output.txt#344-345 it only took a few seconds to install packages though | 20:59 |
| corvus | so i'm leaning toward what clarkb said -- let's just presume this is a dfw problem based on the cacti graphs, and if someone can come up with a better way of identifying affected jobs so we can confirm the actual affected regions, that would be great. | 21:00 |
| clarkb | https://zuul.opendev.org/t/openstack/build/3ae2224e82eb49a3b41584f719dfe1f3/log/job-output.txt#545-642 and there | 21:00 |
| clarkb | oh wait the second link needs to have a longer selection | 21:01 |
| clarkb | but its on the order of half a minute total not half a minute per package | 21:01 |
| opendevreview | James E. Blair proposed openstack/project-config master: Restore max-servers in rax-ord and rax-iad https://review.opendev.org/c/openstack/project-config/+/945654 | 21:02 |
| corvus | i think we should do that ^ and boot a new mirror server in dfw | 21:02 |
| clarkb | +2 on that change from me. I can start spinning up the mirror unless someone else wants to | 21:02 |
| fungi | already approved | 21:03 |
| clarkb | I have lots of recent practice with launching nodes | 21:03 |
| fungi | the second timed_out build i selected at random was in rax-dfw (functional testing for cinder): https://zuul.opendev.org/t/openstack/build/7cfc840183b5421a8db60a05c6dae8c1 | 21:04 |
| clarkb | https://zuul.opendev.org/t/openstack/build/7cfc840183b5421a8db60a05c6dae8c1/log/job-output.txt#371-372 note the time difference to the first example | 21:04 |
| clarkb | that took almost 12.5 minutes | 21:04 |
| clarkb | anyway I'm going to focus on a new mirror for a bit | 21:04 |
| fungi | thanks! | 21:05 |
| clarkb | it will be noble because I may as well | 21:05 |
| clarkb | maybe you can push up a change to reduce the ttl the two cname records for the mirror? | 21:05 |
| fungi | on it | 21:05 |
| clarkb | and get that deployed while I'm building the new server. Thanks | 21:05 |
| fungi | oh, actually do we need that? | 21:08 |
| fungi | yeah, i guess it'll still make the additional cnames take effect sooner | 21:08 |
| fungi | or not, the systems we care about in that regard will have cold caches anyway | 21:09 |
| fungi | clarkb: ^ we're not altering the existing cname records, only adding new ones, right? | 21:09 |
| clarkb | no I was thinking about alterning the existing ones to have smaller ttls | 21:09 |
| clarkb | you're right that nodes would start with cold caches so it would only be a problem for ongoing lookups after initial job startup | 21:10 |
| clarkb | which maybe matters less | 21:10 |
| fungi | how short would you want them for this purpose? something super short like 30 seconds so a node will go back and forth between different mirrors? | 21:10 |
| fungi | we're not going to see even distribution this way regardless, i don't think fiddling with the ttls will change that | 21:11 |
| clarkb | I usually reduce to 300 seconds | 21:12 |
| clarkb | I'm fine with not changing it if you think it is unnecessary | 21:13 |
| opendevreview | Merged opendev/system-config master: Update the IRC accessbot to python3.12 https://review.opendev.org/c/opendev/system-config/+/944405 | 21:13 |
| fungi | i guess my question is would you want to keep both cnames at a low ttl indefinitely in this case? | 21:13 |
| clarkb | the new server is booting and I'ev created its volume. Once booted I'll attach the volume and get it mounted properly then start pushing changes to enroll it | 21:13 |
| clarkb | no I was thinking it would just be for the change over to the new server | 21:13 |
| clarkb | and the ttl could be increased to our hour long default later | 21:14 |
| fungi | oh, you're going to replace the existing server as well as add a second new server? | 21:14 |
| clarkb | I'm only going to replace the server right now | 21:14 |
| clarkb | per the plan corvus proposed | 21:15 |
| fungi | so right now the cnames point to mirror02, but we're going to round-robin between new 03 and 04? | 21:15 |
| * fungi re-reads the plan, had previously read the earlier round-robin suggestion into it | 21:15 | |
| clarkb | my intention was to boot a new server and update mirror to point at mirror03. then see if that server does better | 21:15 |
| clarkb | if it does then we're done. if it doesn't then we can round robin 02 and 03 | 21:15 |
| clarkb | from 20:47:20 | 21:16 |
| corvus | that's the plan in my brain too | 21:16 |
| fungi | okay, that's definitely where i got confused. when corvus said "and boot a new mirror server in dfw" i thought he meant so we could round-robin requests between the existing one and the new one, not for replacing the existing one with a new one | 21:16 |
| corvus | por que no los dos | 21:16 |
| corvus | two plans for the price of one | 21:16 |
| opendevreview | Jeremy Stanley proposed opendev/zone-opendev.org master: Preemptively lower TTL for mirror*.dfw.rax CNAMEs https://review.opendev.org/c/opendev/zone-opendev.org/+/945655 | 21:16 |
| fungi | now we're on the same page ;) | 21:17 |
| corvus | +3 | 21:18 |
| fungi | looks like i stuck the ttl at the wrong tabstop in one of the two records, but bind won't care and we're removing them again shortly regardless | 21:19 |
| clarkb | its between the name and the IN thats all that matters | 21:19 |
| fungi | or no, one of them just has more tabs than the other | 21:19 |
| fungi | yeah, it's all whitespace | 21:19 |
| opendevreview | Merged openstack/project-config master: Restore max-servers in rax-ord and rax-iad https://review.opendev.org/c/openstack/project-config/+/945654 | 21:19 |
| fungi | just my ocd getting the better of me again | 21:20 |
| fungi | the accessbot change failed infra-prod-run-accessbot in deploy | 21:22 |
| fungi | TASK [Run accessbot] non-zero return code | 21:23 |
| fungi | https://paste.opendev.org/show/bVee2HZdsSTODhvEse6U/ | 21:24 |
| clarkb | the server add volume command is terribly slow. Hasn't returned yet | 21:25 |
| fungi | AttributeError: module 'ssl' has no attribute 'wrap_socket' | 21:25 |
| clarkb | bah I guess we revert. I seem to remember fixing similar issues elsewhere. Jeeypb maybe | 21:25 |
| clarkb | its a solveable problem but does need some effort so a revert is probably best | 21:25 |
| fungi | i'm trying to recall | 21:25 |
| clarkb | lsblk shows the volume on the server. Just waiting for volume list to agree then I'll proceed with formatting it and all that fun stuff | 21:26 |
| fungi | in this case we're passing a wrapper to irc.connection.Factory() | 21:26 |
| opendevreview | Merged opendev/zone-opendev.org master: Preemptively lower TTL for mirror*.dfw.rax CNAMEs https://review.opendev.org/c/opendev/zone-opendev.org/+/945655 | 21:28 |
| fungi | looks like we fixed it here: https://opendev.org/openstack/project-config/src/branch/master/tools/check_irc_access.py#L145-L151 | 21:30 |
| fungi | i'll propose a similar patch | 21:30 |
| fungi | https://review.opendev.org/c/openstack/project-config/+/926825 was where you did it | 21:31 |
| opendevreview | Jeremy Stanley proposed opendev/system-config master: Accessbot fix for running on Python 3.12 https://review.opendev.org/c/opendev/system-config/+/945657 | 21:38 |
| opendevreview | Clark Boylan proposed opendev/zone-opendev.org master: Add new noble rax mirror to DNS https://review.opendev.org/c/opendev/zone-opendev.org/+/945658 | 21:38 |
| opendevreview | Clark Boylan proposed opendev/system-config master: Add a new noble mirror in rax https://review.opendev.org/c/opendev/system-config/+/945659 | 21:39 |
| opendevreview | Clark Boylan proposed opendev/zone-opendev.org master: Point mirror.dfw.rax at the new noble mirror https://review.opendev.org/c/opendev/zone-opendev.org/+/945660 | 21:40 |
| clarkb | I think those three changes should do it | 21:40 |
| fungi | all three lgtm, approved the first | 21:41 |
| fungi | and with that, i need to go cook dinner | 21:41 |
| corvus | +2 on all 3 | 21:44 |
| opendevreview | Merged opendev/zone-opendev.org master: Add new noble rax mirror to DNS https://review.opendev.org/c/opendev/zone-opendev.org/+/945658 | 21:45 |
| clarkb | I'll approve the inventory update as soon as ^ deploys | 21:46 |
| clarkb | and records resolve | 21:46 |
| clarkb | fungi: re https://review.opendev.org/c/opendev/system-config/+/945657/1/docker/accessbot/accessbot.py the comment has thing about our testing before that was true but isn't rue in this context | 21:50 |
| clarkb | do you want to update the comment? or try another approach or maybe we just revert for now? | 21:50 |
| clarkb | records are resolving for me now I'm approving the inventory update | 21:52 |
| clarkb | and I'll take the wait for that as an opportunity for a break | 21:53 |
| fungi | https://github.com/jaraco/irc/pull/221/files seems to be the corresponding reference update | 22:02 |
| opendevreview | Jeremy Stanley proposed opendev/system-config master: Accessbot fix for running on Python 3.12 https://review.opendev.org/c/opendev/system-config/+/945657 | 22:07 |
| clarkb | fungi: +2 from me on ^ do you think we should just go ahead and approve it? | 22:18 |
| opendevreview | Merged opendev/system-config master: Add a new noble mirror in rax https://review.opendev.org/c/opendev/system-config/+/945659 | 22:41 |
| clarkb | its going to be a little bit until that fully deploys the server (and new mirrors do an afs build too). But once apache is serving content I expect to see I can approve the next change to flip dns over | 22:44 |
| clarkb | I was just able to get 22.8MB/s copying from mirror02 to paste over the 10 network interface | 22:46 |
| clarkb | I'm now going to compare with mirror03 | 22:47 |
| clarkb | 87MB/s | 22:48 |
| fungi | clarkb: yeah, if 945657 doesn't run successfully (it should retrigger that deploy job), then i can revisit it again tomorrow. if it's broken for a few days it's not the end of the world | 22:54 |
| clarkb | ok I approved it | 22:55 |
| fungi | it only ever runs if we change the script or the config for it, which happens maybe on a ~monthly cadence at most these days | 22:56 |
| fungi | if we have an urgent config update to land for it, then we always have the revert option anyway | 22:57 |
| clarkb | we probably run it daily too? | 22:57 |
| clarkb | actually I think I see a bug | 22:57 |
| fungi | oh | 22:57 |
| clarkb | review updated | 22:58 |
| fungi | d'oh! | 22:59 |
| fungi | now that's almost as embarrasing as leaving a clearly commented test configuration when copying into the production script | 22:59 |
| opendevreview | Jeremy Stanley proposed opendev/system-config master: Accessbot fix for running on Python 3.12 https://review.opendev.org/c/opendev/system-config/+/945657 | 23:00 |
| fungi | thanks again! | 23:00 |
| * fungi sighs | 23:00 | |
| clarkb | if you like you can apply the same fix to the test you found the bad fix from | 23:01 |
| clarkb | that would confirm this works before we approve it if you'd like to double check. Otherwise I can reapprove | 23:02 |
| clarkb | +2'd for now anyway | 23:02 |
| fungi | oh, good idea | 23:03 |
| clarkb | almost to the mirror deployment job now | 23:03 |
| opendevreview | Jeremy Stanley proposed openstack/project-config master: Update SSL use in our IRC access check script https://review.opendev.org/c/openstack/project-config/+/945662 | 23:07 |
| opendevreview | Jeremy Stanley proposed opendev/system-config master: Accessbot fix for running on Python 3.12 https://review.opendev.org/c/opendev/system-config/+/945657 | 23:07 |
| clarkb | I believe the project-config change is self testing (thats how the fix came up we wanted to default to noble for the job and it broke) | 23:09 |
| clarkb | openafs is building on mirror03 | 23:09 |
| fungi | yeah, that's why i added the depends-on | 23:10 |
| fungi | - project-config-irc-access https://zuul.opendev.org/t/openstack/build/def8d5ab69964d4ebb5a5e9af718925b : SUCCESS in 6m 30s | 23:18 |
| clarkb | I think you can approve that one. I +2'd | 23:18 |
| fungi | i guess it worked | 23:18 |
| clarkb | then approve the other | 23:19 |
| clarkb | the mirror is no longer running gcc so should hopefully complete the deployment job soon | 23:19 |
| fungi | i need to knock off for the evening, but will check in on the accessbot deploy job in the morning before my meeting | 23:20 |
| clarkb | https://mirror03.dfw.rax.opendev.org/ that has stuff now | 23:20 |
| clarkb | I'm going to approve the the dns swap and that way periodic jobs at 02:00 should generate data for us | 23:21 |
| corvus | nice | 23:22 |
| opendevreview | Merged opendev/zone-opendev.org master: Point mirror.dfw.rax at the new noble mirror https://review.opendev.org/c/opendev/zone-opendev.org/+/945660 | 23:25 |
| opendevreview | Merged openstack/project-config master: Update SSL use in our IRC access check script https://review.opendev.org/c/openstack/project-config/+/945662 | 23:32 |
| corvus | i guess the mirror hosts are in cacti by their cnames, so we'll just see the graphs cutover nowish | 23:35 |
| clarkb | ya new mirror is what I get out of dns now | 23:37 |
| corvus | new data apparent in cacti (can see the discontinuity) | 23:54 |
| clarkb | corvus: are we anywhere near the total bw from before? or is it too early to say if this is different? | 23:57 |
| corvus | it was pretty low anyway (due to time of day? plus 623?). also, i guess we would expect a slowly (2 hours?) rolling cutover anyway with tcp connections to the old server | 23:58 |
| corvus | https://imgur.com/nutfRgA | 23:59 |
Generated by irclog2html.py 2.17.3 by Marius Gedminas - find it at https://mg.pov.lt/irclog2html/!
{kind=link}