| opendevreview | Merged opendev/system-config master: Accessbot fix for running on Python 3.12 https://review.opendev.org/c/opendev/system-config/+/945657 | 00:04 |
|---|---|---|
| opendevreview | Merged opendev/irc-meetings master: Move Large Scale SIG meeting one hour earlier https://review.opendev.org/c/opendev/irc-meetings/+/945633 | 07:49 |
| *** sfinucan is now known as stephenfin | 10:23 | |
| fungi | looks like infra-prod-run-accessbot succeeded on deploy for 945657 | 12:41 |
| opendevreview | Merged opendev/system-config master: docs: Switch a mailing list to default moderation https://review.opendev.org/c/opendev/system-config/+/944893 | 13:06 |
| fungi | i ended up doing that ^ for another list just now | 13:07 |
| fungi | https://lists.openstack.org/archives/list/legal-discuss@lists.openstack.org/message/AJFK6RDQMR27E45TV4HT6HO2D3QSCKPH/ | 13:08 |
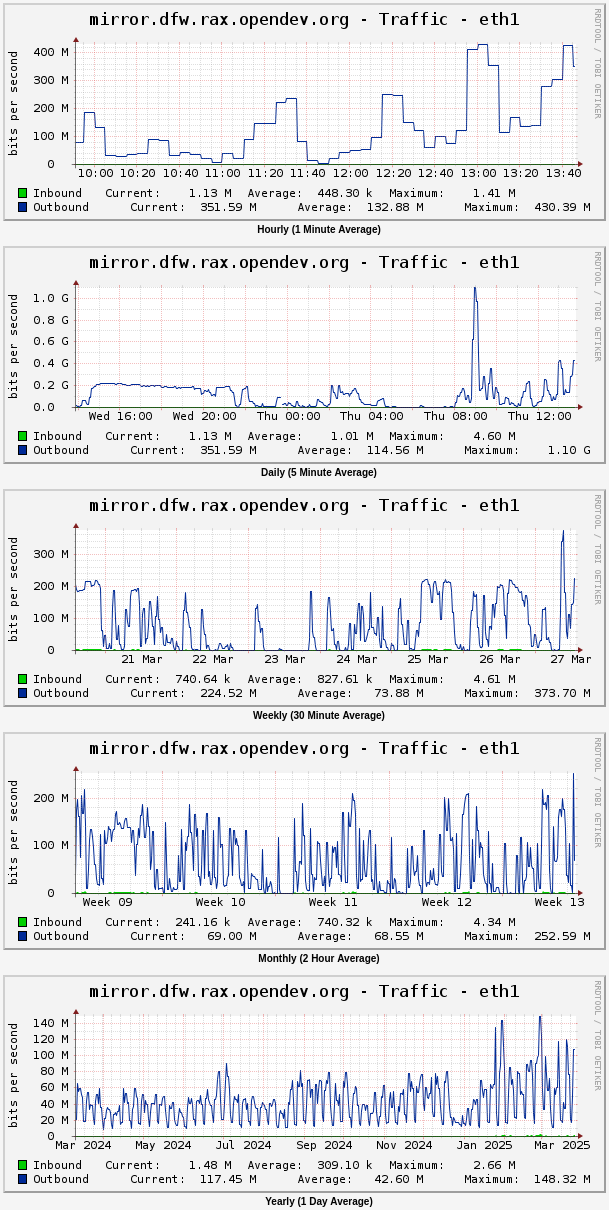
| fungi | infra-root: jamesdenton_: progress report on the replaced mirror.dfw.rax.opendev.org network performance... checking the graphs in cacti the new server instance does not seem to have its eth1 traffic constrained the way we saw impacting the old one, so we can probably restore our max-servers value there to normal now | 13:49 |
| fungi | i'll push up a change for it | 13:49 |
| jamesdenton_alt | thanks fungi | 13:49 |
| jamesdenton_alt | still looking to investigate further on my end | 13:49 |
| fungi | we haven't deleted the old server instance, merely shifted all our traffic to a replacement as of just before midnight utc | 13:50 |
| jamesdenton_alt | ok cool | 13:50 |
| fungi | here's what the graph looks like now: https://fungi.yuggoth.org/tmp/dfw-mirror-traffic-post-replacement.png | 13:53 |
| opendevreview | Jeremy Stanley proposed openstack/project-config master: Restore max-servers in rax-dfw https://review.opendev.org/c/openstack/project-config/+/945707 | 13:58 |
| corvus | wow it managed a 1Gbps spike. that's a lot different than the old one. | 14:07 |
| corvus | very comparable to the other 2 regions now | 14:07 |
| fungi | yep | 14:36 |
| corvus | nice hunch clarkb :) | 14:42 |
| opendevreview | Dan Smith proposed openstack/project-config master: Add viommu support to vexxhost ubuntu-noble https://review.opendev.org/c/openstack/project-config/+/945715 | 15:00 |
| clarkb | I've approved the restoration of max-servers in dfw. rax iad's mirror is on the todo list for replacement due to its age. I'm going to start on that since I already have half the ingredients sorted out in my gnu screen mixing bowl | 15:11 |
| clarkb | but first catching up on morning things. Looks like accessbot is happy again. Thank you for sorting that out fungi | 15:14 |
| opendevreview | Merged openstack/project-config master: Restore max-servers in rax-dfw https://review.opendev.org/c/openstack/project-config/+/945707 | 15:18 |
| opendevreview | Dan Smith proposed openstack/project-config master: Add viommu support to vexxhost ubuntu-noble https://review.opendev.org/c/openstack/project-config/+/945715 | 15:38 |
| clarkb | as a heads up I have a family lunch thing today so will be out midday for a bit | 15:42 |
| fungi | take all the time you need. i'll probably need to cook at some point but i don't plan to go anywhere today | 15:43 |
| clarkb | also selinux, apparmor, xmonad, and grub just updated. This could be an exciting reboot | 15:49 |
| clarkb | (yes tumbleweed runs both selinux and apparmor apparently) | 15:49 |
| clarkb | new iad mirror is launching. And I survived a local reboot | 16:14 |
| fungi | sounds like i will actually be disappearing briefly this afternoon, maybe the same time as clarkb, but it probably shouldn't be for more than 45 minutes | 16:33 |
| clarkb | things seem quiet so probably not a big deal | 16:33 |
| fungi | yeah, that was my reasoning as well | 16:33 |
| fungi | we decided going out to grab a quick mid-afternoon meal at the pub around the corner would be less impact to day than trying to cook dinner | 16:34 |
| fungi | chris is trying to work around her day full of appointments and i have a massive to-do list i'm trying to tackle | 16:35 |
| slittle | https://review.opendev.org/c/starlingx/root/+/945717 seems to be stuck | 16:38 |
| opendevreview | Clark Boylan proposed opendev/zone-opendev.org master: Add the new Noble IAD rackspace Mirror to DNS https://review.opendev.org/c/opendev/zone-opendev.org/+/945727 | 16:39 |
| opendevreview | Clark Boylan proposed opendev/system-config master: Add the new Noble IAD Rackspace Mirror to Inventory https://review.opendev.org/c/opendev/system-config/+/945728 | 16:42 |
| opendevreview | Clark Boylan proposed opendev/zone-opendev.org master: Switch rackspace iad to the new noble mirror https://review.opendev.org/c/opendev/zone-opendev.org/+/945730 | 16:44 |
| fungi | looking | 16:44 |
| clarkb | slittle: fungi: its parent isn't approved | 16:45 |
| fungi | slittle: you haven't approved the parent change https://review.opendev.org/c/starlingx/root/+/945710 yet | 16:45 |
| clarkb | infra-root I think the series of three changes above to add the new iad mirror is ready to go | 16:48 |
| clarkb | I'm happy to +A them as things update if they get reviews | 16:48 |
| clarkb | then I'll push out cleanup changes when we're happy with the new system. I'm not cleaning up the new mirror in dfw because jamesdenton_alt was still looking at it | 16:49 |
| jamesdenton_alt | thank you | 16:49 |
| clarkb | er cleaning up the old mirror but I think people understood | 16:49 |
| fungi | where "cleaning up" means `openstack server delete ...` | 16:51 |
| fungi | yeah, we can hold that step off as long as needed | 16:51 |
| slittle | ah, I see it | 16:56 |
| opendevreview | Dan Smith proposed openstack/project-config master: Add viommu support to vexxhost ubuntu-noble https://review.opendev.org/c/openstack/project-config/+/945715 | 17:22 |
| opendevreview | Merged opendev/zone-opendev.org master: Add the new Noble IAD rackspace Mirror to DNS https://review.opendev.org/c/opendev/zone-opendev.org/+/945727 | 17:29 |
| clarkb | that name resolves I'm approving the inventory udpate now | 17:35 |
| opendevreview | Merged openstack/project-config master: Add viommu support to vexxhost ubuntu-noble https://review.opendev.org/c/openstack/project-config/+/945715 | 17:38 |
| fungi | that ovh login notification just now was me, i was just checking the billing since i needed to do the same for my own personal account | 17:39 |
| clarkb | ack thanks for letting us know | 17:42 |
| fungi | looks like our credits are still active | 17:43 |
| clarkb | the matrix eavesdrop bot uses matrix-nio and is all async which makes me suspect it is less likely to have python3.12 problems. I can approve it after lunch today if I have time | 17:48 |
| opendevreview | Merged opendev/system-config master: Add the new Noble IAD Rackspace Mirror to Inventory https://review.opendev.org/c/opendev/system-config/+/945728 | 18:17 |
| Clark[m] | I'm off to lunch so will have to check the new mirror afterwards | 18:50 |
| fungi | i'm heading out shortly as well, but should be back fairly soon, by 20:00 utc for sure | 19:03 |
| fungi | okay, out for a bit, brb | 19:17 |
| fungi | been back for a few, seems like everything's still quiet | 20:24 |
| clarkb | https://mirror02.iad.rax.opendev.org/ is up for me I'll approve the dns update next | 20:29 |
| fungi | cool | 20:30 |
| fungi | i agree, has content | 20:30 |
| opendevreview | Merged opendev/zone-opendev.org master: Switch rackspace iad to the new noble mirror https://review.opendev.org/c/opendev/zone-opendev.org/+/945730 | 20:31 |
| opendevreview | Clark Boylan proposed opendev/system-config master: Remove the old rax iad mirror from the inventory https://review.opendev.org/c/opendev/system-config/+/945774 | 20:38 |
| opendevreview | Clark Boylan proposed opendev/zone-opendev.org master: Cleanup mirror01.iad.rax.opendev.org records https://review.opendev.org/c/opendev/zone-opendev.org/+/945776 | 20:40 |
| clarkb | whenever we're happy with the new instance I think it is safe to merge those two changes | 20:41 |
| clarkb | then I can delete the old instance | 20:41 |
| clarkb | and I'm going to approve the matrix eavesdrop change now | 20:42 |
| clarkb | the other thing I've got on my mind is booting a new gerrit server. I was going to do that this week but then the noble kernel issues hit. I'll probably plan to do it next week kernel update or not | 21:17 |
| clarkb | I know that we have had discussion about whether or not the gerrit server should consider a location move. Every location seems to have its own downsides but the current one seems relatively minor to me (but of course I'm biased as my home isp doesn't offer ipv6 connectivity) | 21:18 |
| clarkb | infra-root maybe give that a consideration and say something if you think the gerrit server shouldn't be a enw server in vexxhost ymq | 21:19 |
| opendevreview | Merged opendev/system-config master: Update matrix eavesdrop runtime to python3.12 https://review.opendev.org/c/opendev/system-config/+/944402 | 21:19 |
| clarkb | the upsides for that location are the size of the bootable VM and general performance keeps up with our current demands. The downside is that ipv6 routing to there is not working from some networks | 21:19 |
| fungi | we moved it to vexxhost because, back when we were experiencing significant unbounded memory leaks, we needed a very large flavor... do we still? | 21:20 |
| clarkb | that did enqueue the eavesdrop deployment job so once that deploys I can go send a message to the zuul room and see that it gets logged | 21:20 |
| fungi | even if we leave review.o.o in the same provider, should we consider smaller flavor for the replacement? | 21:21 |
| clarkb | memory consumption has reduced on average but I believe that we still see it spiek when there is a lot of querying going on | 21:21 |
| clarkb | I'm not personally comfortable with going smaller just with what we know of gerrit historically and how it behaves | 21:22 |
| clarkb | when you need memory you really need it | 21:22 |
| clarkb | it is also particularly useful when doing things like reindexing | 21:22 |
| fungi | fair, though i haven't seen it even come close to 50% of its available memory lately | 21:22 |
| clarkb | which makes upgrades much easier and shortens downtime | 21:22 |
| clarkb | we only let gerrit use up to 3/4 fwiw | 21:23 |
| fungi | in part, i tink, because we limit what the jvm is allowed to allocate? | 21:23 |
| clarkb | then the rest we try to keep for filesystem caching and the like | 21:23 |
| fungi | ah okay | 21:23 |
| clarkb | yup exactly the limit is 96gb iirc and we have 128gb | 21:23 |
| corvus | funny you should say that; i just switched to my laptop while i wait for my desktop oom killer to make up its mind (zuul unit test run went awry) | 21:24 |
| corvus | "when you need memory you need it" | 21:24 |
| clarkb | I'll put it this way: we spent years fighting to squeeze gerrit into a small box and managing gerrit is much easier today for many reasons but one of which I strongly suspect is we stopped squeezing it to fit | 21:25 |
| fungi | fair, with approaching 2 months uptime it's using about 1/3 ram active, 1/3 buffers+cache, and 1/3 unused | 21:25 |
| clarkb | so unless there is a strong reason to downsize then I'd like to stay at hte current allocation | 21:26 |
| fungi | yeah, if the provider isn't asking us to scale back, i'm not overly concerned | 21:26 |
| corvus | ah, it finally made a choice. my desktop session. nice. | 21:26 |
| corvus | clarkb: sgtm | 21:26 |
| fungi | you didn't need it anyway | 21:27 |
| clarkb | https://meetings.opendev.org/irclogs/%23zuul/%23zuul.2025-03-27.log matrix-eavesdrop appears to still work after being updated | 21:28 |
| clarkb | that last message from me was after the restart | 21:28 |
| fungi | awesome | 21:29 |
| clarkb | corvus: this way you can still check the test results maybe :) | 21:29 |
| corvus | if only i had run them in screen :) | 21:31 |
| clarkb | how did https://review.opendev.org/c/opendev/lodgeit/+/944410 and https://review.opendev.org/c/opendev/lodgeit/+/945135 happen | 21:31 |
| clarkb | I wrote the same change twice fun | 21:31 |
| clarkb | I'm going to double check they are identical and abandon the unreviewed one. Then maybe we can proceed with upgrading lodgeit | 21:32 |
| clarkb | they do appaer to be identical | 21:33 |
| clarkb | I abandoned 944410 and approved 945135 | 21:35 |
| fungi | sgtm | 21:37 |
| clarkb | and then https://review.opendev.org/c/opendev/system-config/+/945774 is ready to start cleaning up the old iad mirror whenever we feel we're ready. I'm happy to wait for tomorrow and dobule check cacti shows the new server handling periodic job demand before cleaning stuff up | 21:40 |
| clarkb | that does seem to be a good test for the mirrors. The spike from those jobs on dfw was really noticeable | 21:41 |
| fungi | agreed | 21:42 |
| ianw | (btw ipv6 to ymq from .au has been generally fine for me. i do remember one blip) | 21:52 |
| fungi | seems like it's been worse from/western eu | 21:53 |
| clarkb | ianw: I think it is frickler's isp that complains the most out of the people we've heard from. And I guess technically the prefix isn't being advertised properly but every other isp seems to work so I dunno | 21:53 |
| opendevreview | Merged opendev/lodgeit master: Bump lodgeit up to python3.12 https://review.opendev.org/c/opendev/lodgeit/+/945135 | 22:02 |
| clarkb | if that requires manual intervention to deploy the update I'll do that shortly (hourly jobs are enqueued now so not a rush I don't think) | 22:04 |
| clarkb | https://discuss.python.org/t/upcoming-changes-in-the-pypa-wheel-project/85967/12 | 22:05 |
| clarkb | oh ya that merged to lodgeit not system-config so I think it does need a manual bump to go before the daily periodics. I'll get on that shortly | 22:05 |
| clarkb | 8f68b3c9a806 is the current lodgeit image that is running | 22:08 |
| clarkb | Image updated and service restarted. I can still load https://paste.opendev.org/show/bVee2HZdsSTODhvEse6U/ from fungi yesterday | 22:10 |
| clarkb | https://paste.opendev.org/show/bEv2tbiu2zwZCkCg3NoF/ and this new paste pasted | 22:11 |
| fungi | yep, seems to be working just fine | 22:12 |
| clarkb | fwiw it does appear that the service is getting crawled by yet another one of our friends. But I'm not surprised | 22:13 |
| clarkb | this one is using aws ip addrs | 22:13 |
| clarkb | just something to keep in mind if the service starts struggling to be responsing | 22:13 |
| opendevreview | Clark Boylan proposed opendev/lodgeit master: Run lodgeit with granian instead of uwsgi https://review.opendev.org/c/opendev/lodgeit/+/944805 | 22:23 |
| clarkb | that needed a rebase to go on top of the 3.12 update. I'll recheck the system-config change too | 22:23 |
| clarkb | the lodgeit paste granian change did pass testing. However it seems like running more than one worker might not be safe for the database: https://zuul.opendev.org/t/openstack/build/5a73ef6d31e6439fa3577f0e697fb7a3/log/paste99.opendev.org/containers/docker-lodgeit.log I guess I'll just switch to a single worker instead | 23:26 |
| opendevreview | Clark Boylan proposed opendev/system-config master: Run lodgeit with granian https://review.opendev.org/c/opendev/system-config/+/944806 | 23:27 |
| corvus | 2025-03-27 23:27:10,370 ERROR zuul.Launcher: [e: 53eb1c7d3c4247aabc30f29959586571] [req: 4aeac8dff75d4e25b2166a684a2cd819] Error in creating the server. Compute service reports fault: Build of instance 6abcc5cf-a0af-41f6-a277-c53e0b6ca66c aborted: Failed to allocate the network(s), not rescheduling. | 23:28 |
| corvus | that's on raxflex-dfw3 | 23:28 |
| opendevreview | Clark Boylan proposed opendev/system-config master: Run lodgeit with granian https://review.opendev.org/c/opendev/system-config/+/944806 | 23:28 |
| corvus | is that something we should anticipate? or is that an expected error? | 23:28 |
| clarkb | corvus: that is a new error to me. I wonder if that is due to there not being an available floating ip? | 23:29 |
| clarkb | corvus: the cloud launcher creates a /24 network for the internal network which is ~252 useable addresses and we have a max server count of 32 | 23:30 |
| clarkb | I doubt that the problem is our internal network which is why I suspect the problem is the floating ip attachment piece | 23:30 |
| clarkb | however, dependingon the lease time for the IPs in that /24 maybe we are running out of addrs. I'll try to check that | 23:31 |
| corvus | https://grafana.opendev.org/d/6d29645669/nodepool3a-rackspace-flex?orgId=1&from=now-6h&to=now&timezone=utc&var-region=$__all | 23:31 |
| corvus | doesn't look like we hit the max servers in nodepool recently; and there would have been only 2 extra from zuul launcher | 23:31 |
| clarkb | oh its a /20 actually not a /24 | 23:32 |
| clarkb | there is no subnet pool associated to our subnet so not sure how to check dhcp details | 23:35 |
| clarkb | I guess we can ssh into a server and check the laese time from there | 23:35 |
| clarkb | but that doesn't show pool usage | 23:35 |
| corvus | looks like that error has shown up in nodepool 5 times over the past 3 days. in dfw3 and sjc3. | 23:36 |
| corvus | spot checked the most recent incident there too, and it doesn't look like heavy use at the time | 23:37 |
| corvus | the retry in zuul-launcher succeeded in sjc3. so it failed over from dfw3 to sjc3. | 23:40 |
| clarkb | option dhcp-lease-time 43200; | 23:41 |
| clarkb | a 12 hours lease time is a bit long but we'd have to get through 4k ish nodes within that time frame to run out of addrs which seems like a lot | 23:41 |
| clarkb | all that to say it seems unlikely that not having enough free internal ips is at fault. But doing subnet lists the public networks are much smaller so I'm thinking its more likely we couldn't get a floating ip | 23:42 |
| corvus | we have gone through a total of 1600 notes in the almost-24h period of today utc time, across all providers. | 23:44 |
| corvus | wow that was wrong | 23:44 |
| corvus | we have gone through a total of 16000 nodes in the almost-24h period of today utc time, across all providers. | 23:44 |
| corvus | that's more like it | 23:44 |
| corvus | so i agree, it seems unlikely we would hit that limit in one flex region | 23:45 |
| clarkb | ist possible jamesdenton_alt would be willing to check logs on the cloud side if you haev the failed instance uuid | 23:47 |
| clarkb | I guess the other thing to check is where that error originates within nova | 23:48 |
| clarkb | that might give a clue | 23:48 |
| corvus | jamesdenton_alt: `Error in creating the server. Compute service reports fault: Build of instance 6abcc5cf-a0af-41f6-a277-c53e0b6ca66c aborted: Failed to allocate the network(s), not rescheduling.` | 23:48 |
| corvus | jamesdenton_alt: ^ that's an example of an error that we seem to get a few times a day in flex | 23:48 |
| clarkb | _build_networks_for_instance() in nova is what raises the exception that leads to that message | 23:50 |
| clarkb | and looking at that I think this is building the underlying network not the end result which attaches a floating ip | 23:51 |
| clarkb | so while I still think that we likely aren't running out of IPs something else in that process of attaching the networking is going wrong maybe? | 23:51 |
| clarkb | that method has built in retries inside nova too so maybe something they expect to fail occasionally | 23:52 |
| clarkb | and it calls out to neutron | 23:52 |
| clarkb | so ya I suspect that the real interesting info is in the neutron logs but we're isolated from that in what bubbles up to us | 23:53 |
| corvus | sounds like noting the error for our operator friends is the right thing :) | 23:54 |
| clarkb | ++ | 23:54 |
Generated by irclog2html.py 2.17.3 by Marius Gedminas - find it at https://mg.pov.lt/irclog2html/!
{kind=link}